This blog will explain how to archive WM transfer orders and requirements via objects RL_TA and RL_TB. Generic technical setup must have been executed already, and is explained in this blog.
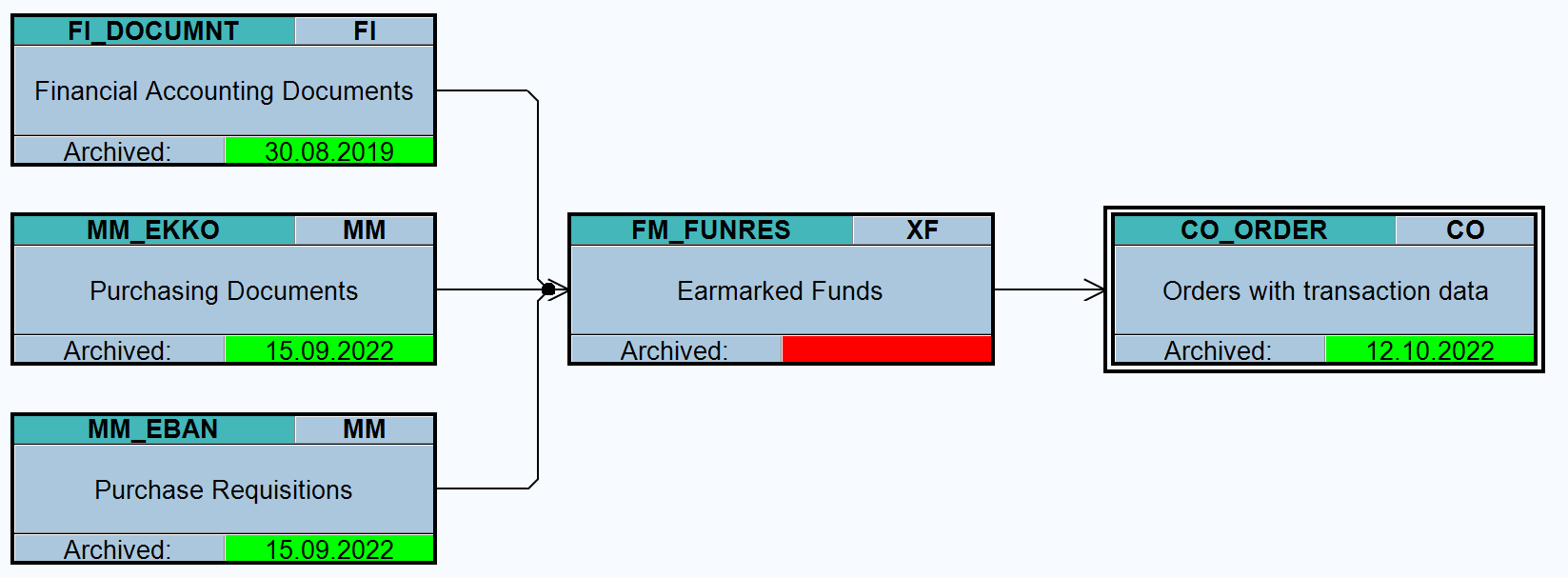
Objects RL_TA and RL_TB
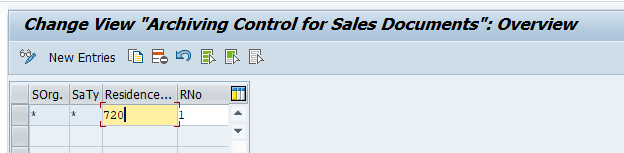
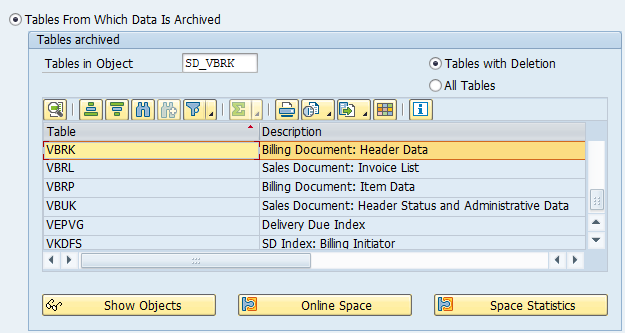
Go to transaction SARA and select object RL_TA and RL_TB.
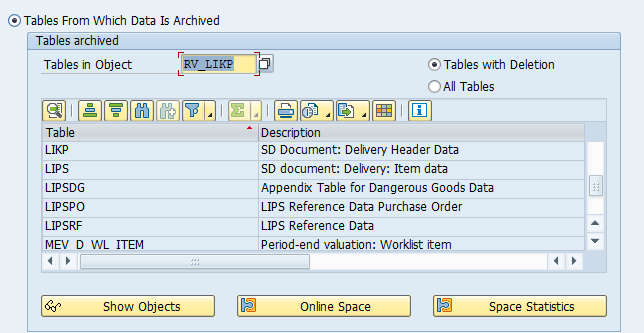
Dependency schedule (no dependencies for both):

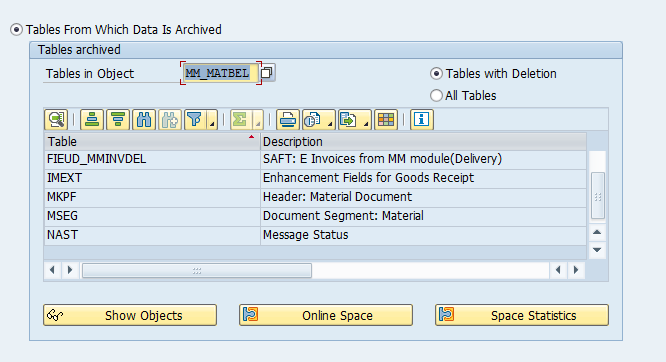
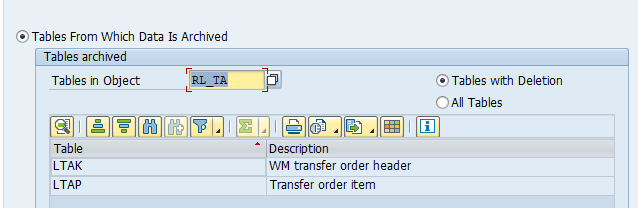
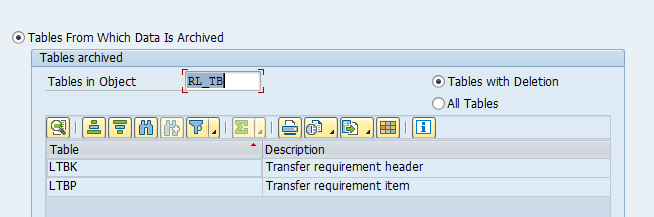
Main tables that are archived:
- LTAK (transfer order header)
- LTAP (transfer order item)
- LTBK (transfer requirement header)
- LTBP (transfer requirement item)
Technical programs and OSS notes
RL_TA:
Write program: RLREOT00S
Delete program: RLREOT10
Read program:RLRT0001
RL_TB:
Write program: RLREOB00S
Delete program: RLREOB10
Read program: RLRB0001
Relevant OSS notes:
- 2590146 – RL_TA: Archive Delete Jobs in Status ‘Finished’
- 3041484 – Is archived WM data in ECC accessible in S/4HANA?
- 3116459 – Unable to Reload Transfer Order Archive (RL_TA )
- 3117335 – Residence time option and status are ignored when you execute the report RLREOT00S or RLREOB00S
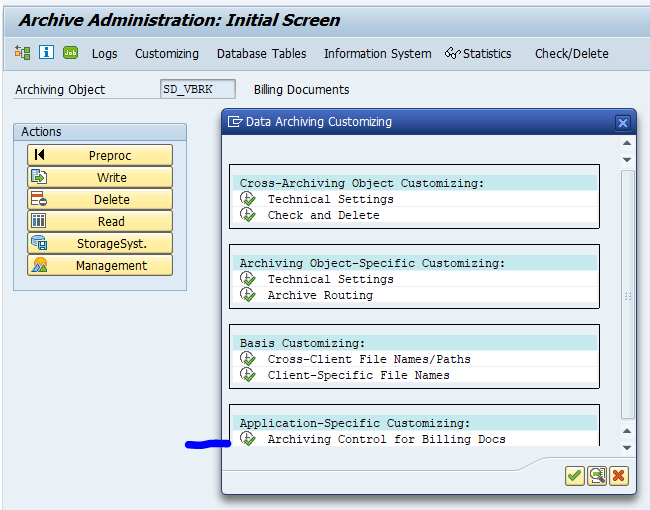
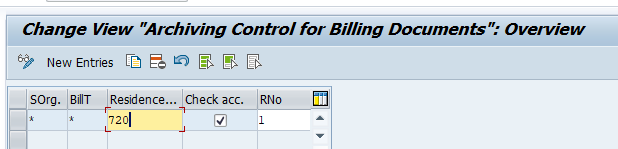
Application specific customizing
RL_TA and RL_TB don’t have application specific customizing.
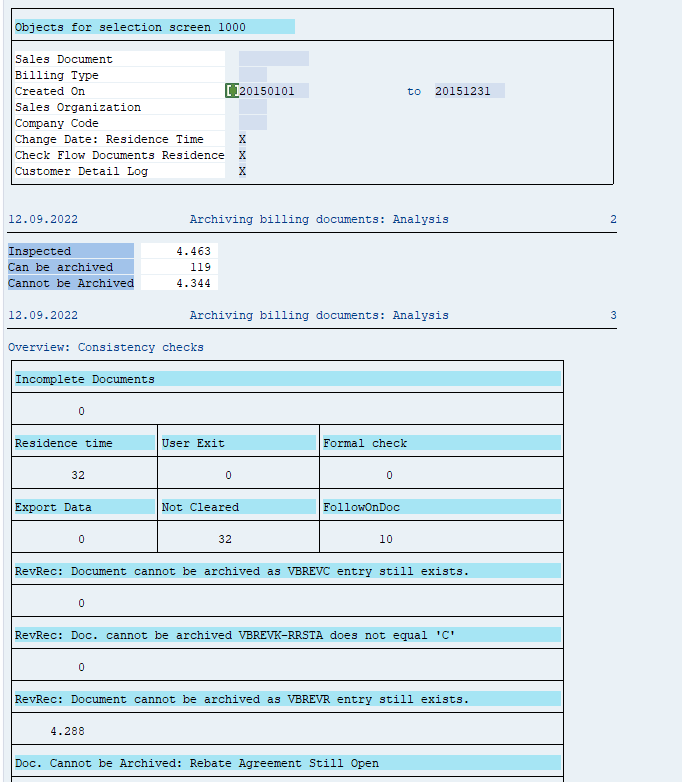
Typically RL_TA and RL_TB will yield 90 to 100% documents that can be archived.
Executing the write run and delete run
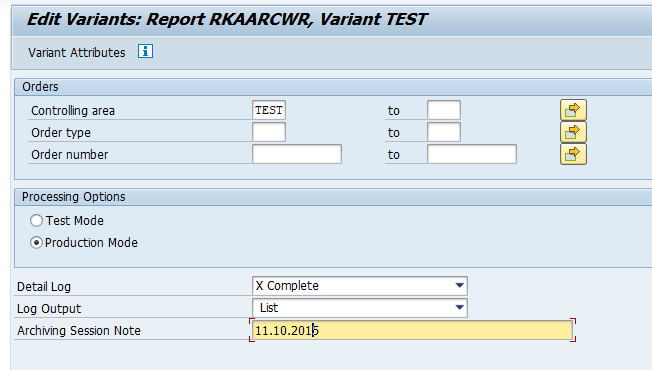
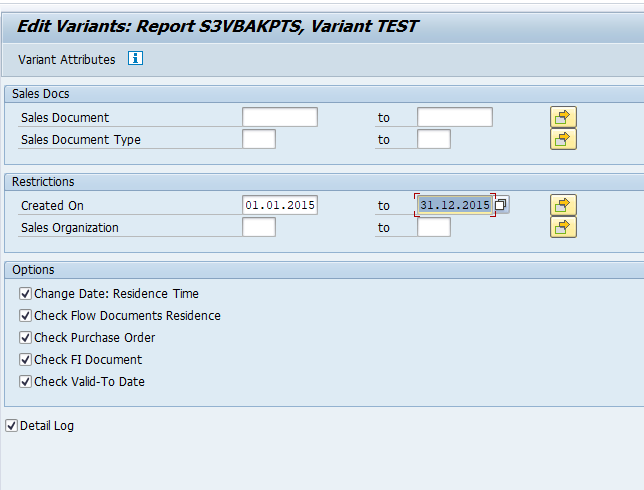
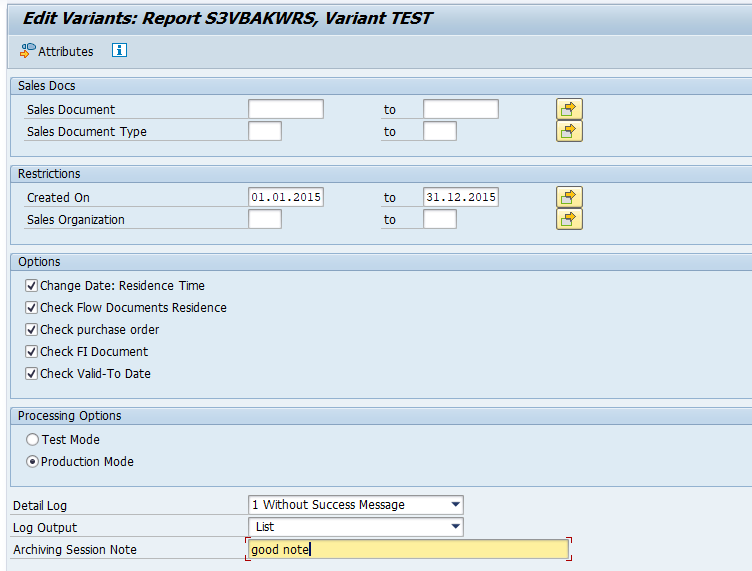
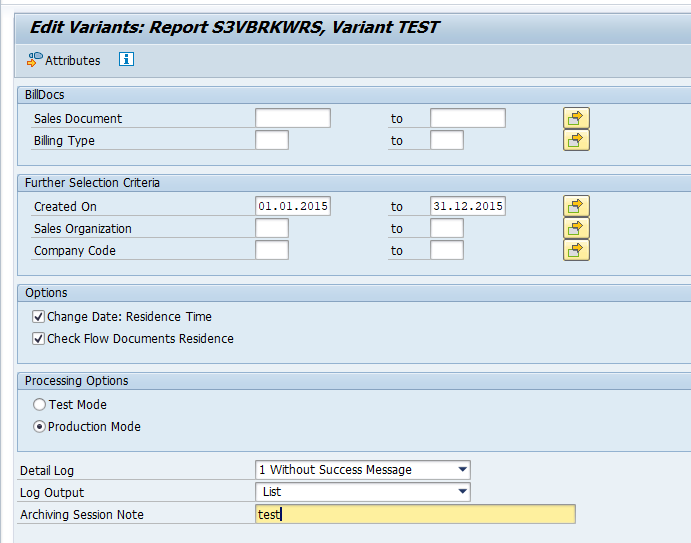
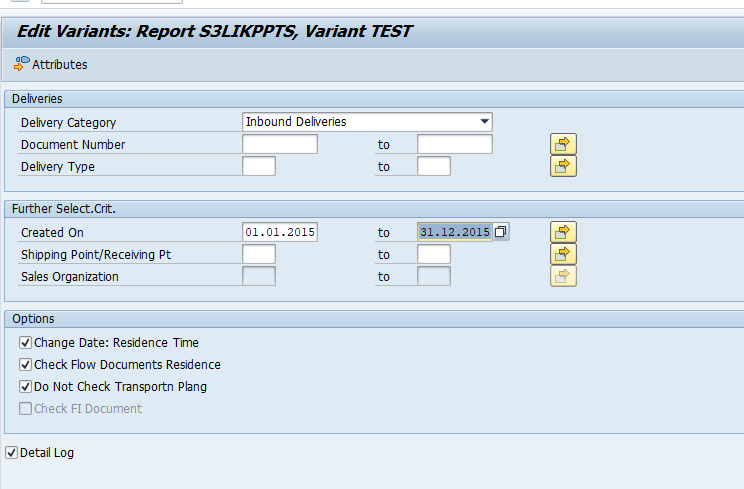
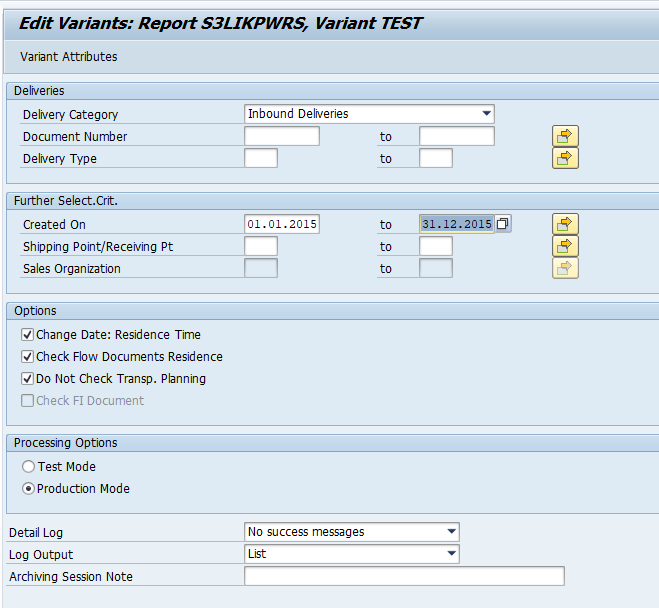
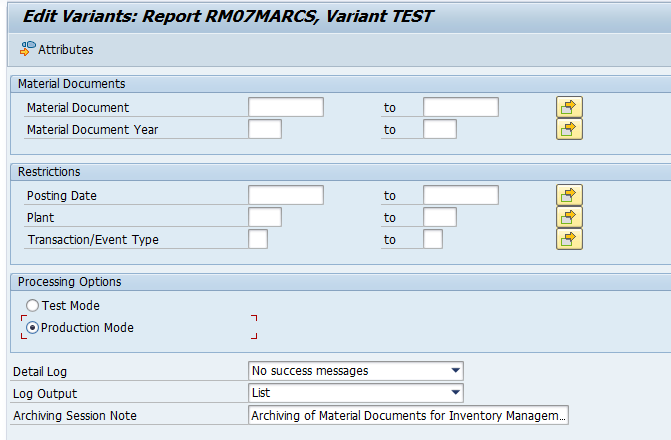
In transaction SARA, RL_TA or RL_TB select the write run:
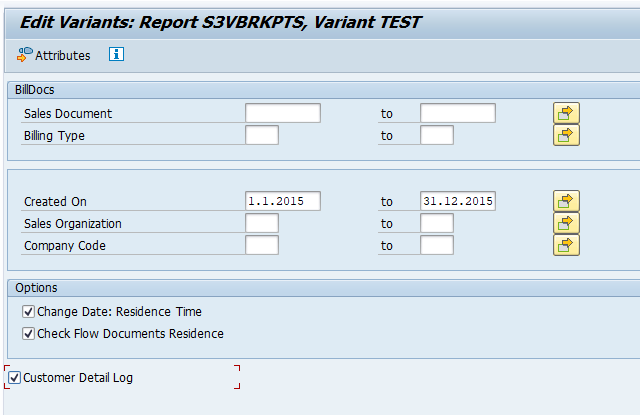
Select your data, save the variant and start the archiving write run.
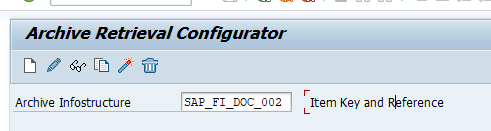
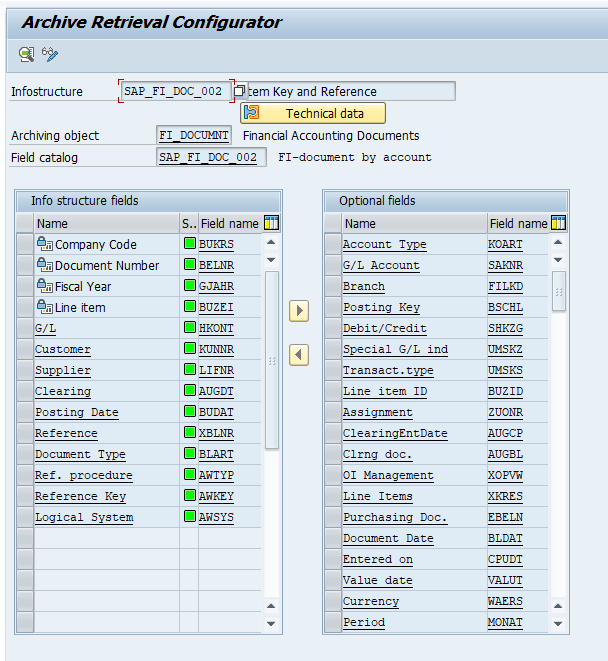
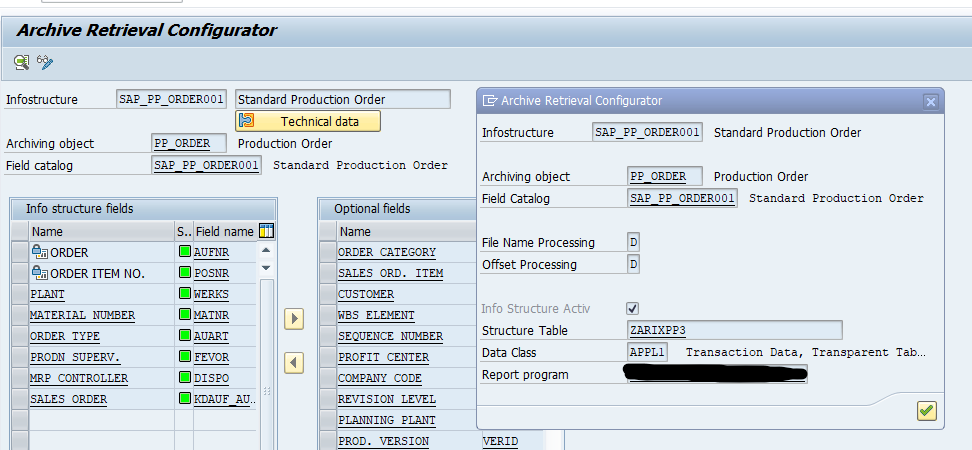
Give the archive session a good name that describes sales warehouse and year. This is needed for data retrieval later on.
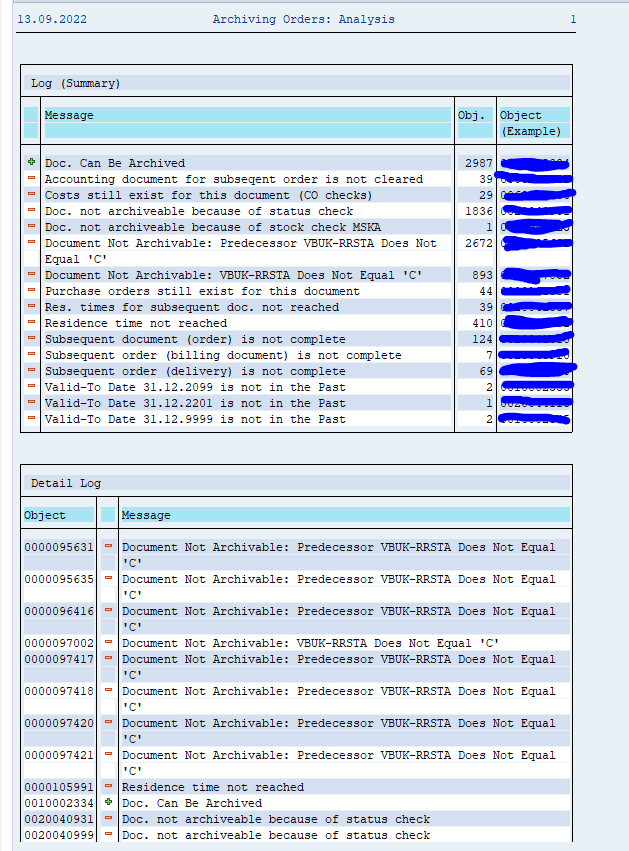
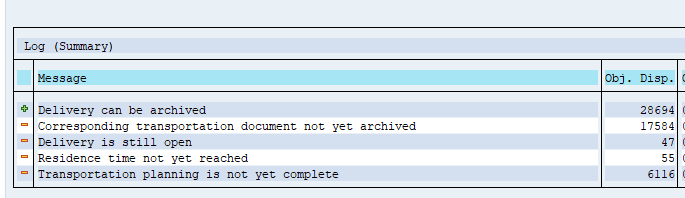
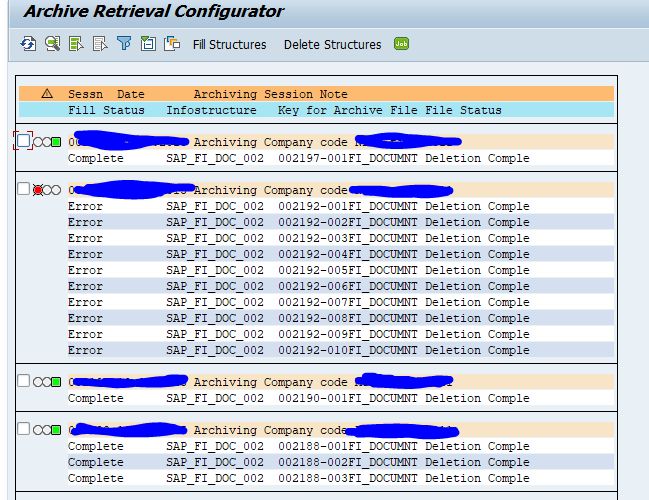
After the write run is done, check the logs. RL_TA and RL_TB archiving has average speed, and a high percentage of archiving (up to 90 to 100%).
Deletion run is standard by selecting the archive file and starting the deletion run.
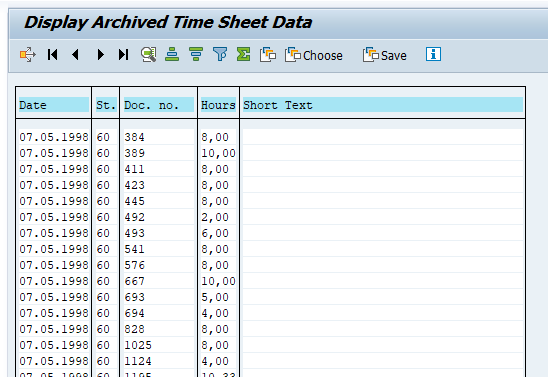
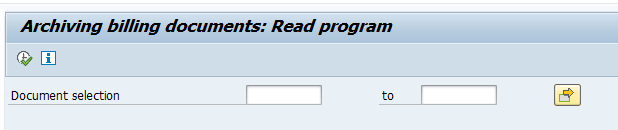
Data retrieval
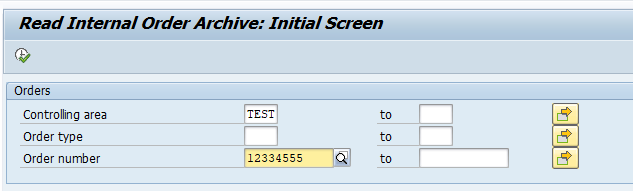
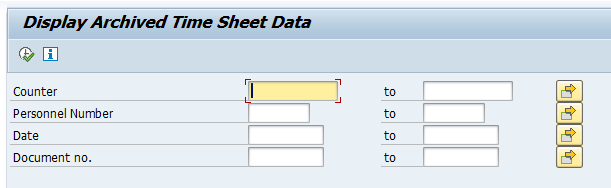
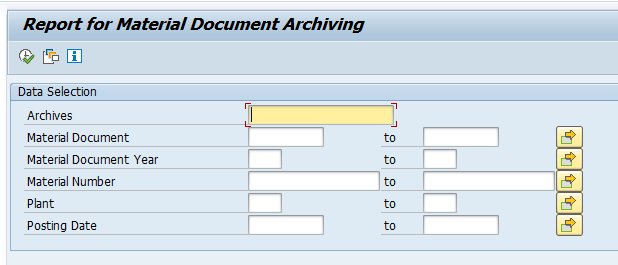
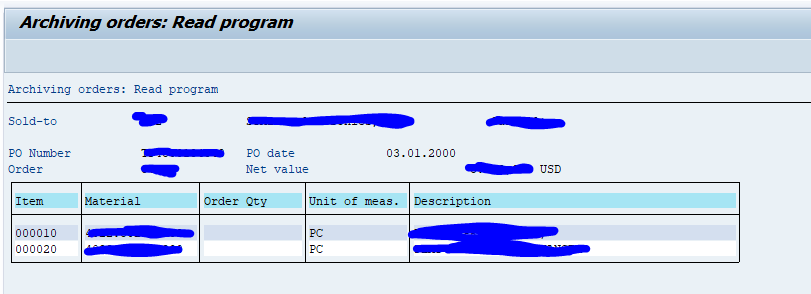
Start the data retrieval program and fill selection criteria for transfer orders:
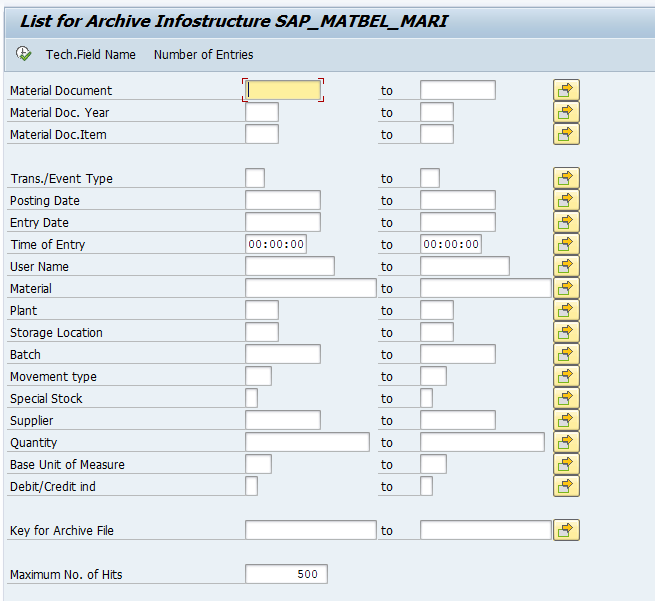
Start the data retrieval program and fill selection criteria for transfer requirements:
In the popup screen select the wanted archive files.