This blog will give tips and tricks for the SAP SNOTE transaction. Questions that will be answered are:
- How to update SNOTE itself?
- How to check if there are new versions available for notes?
- What is TCI?
- Where to find tips on finding correct OSS notes?
- How do I apply a note during upgrade in the shadow system?
- What is the new SNOTE revamp?
- How to find in which SAP transport a note is stored?
If you are looking for way to check which OSS notes are needed, read the ANST blog: the automated notes search tool.
Notes for SNOTE itself
Also SNOTE itself can have bugs or has new functions. Download and implement most recent version of OSS note 1668882 – Note Assistant: Important notes for SAP_BASIS 730,731,740,750,751 to update SNOTE itself.
For the revamped SNOTE also note 3093855 – Note Assistant: Important SAP Notes for the Revamped Note Assistant is required to be updated.
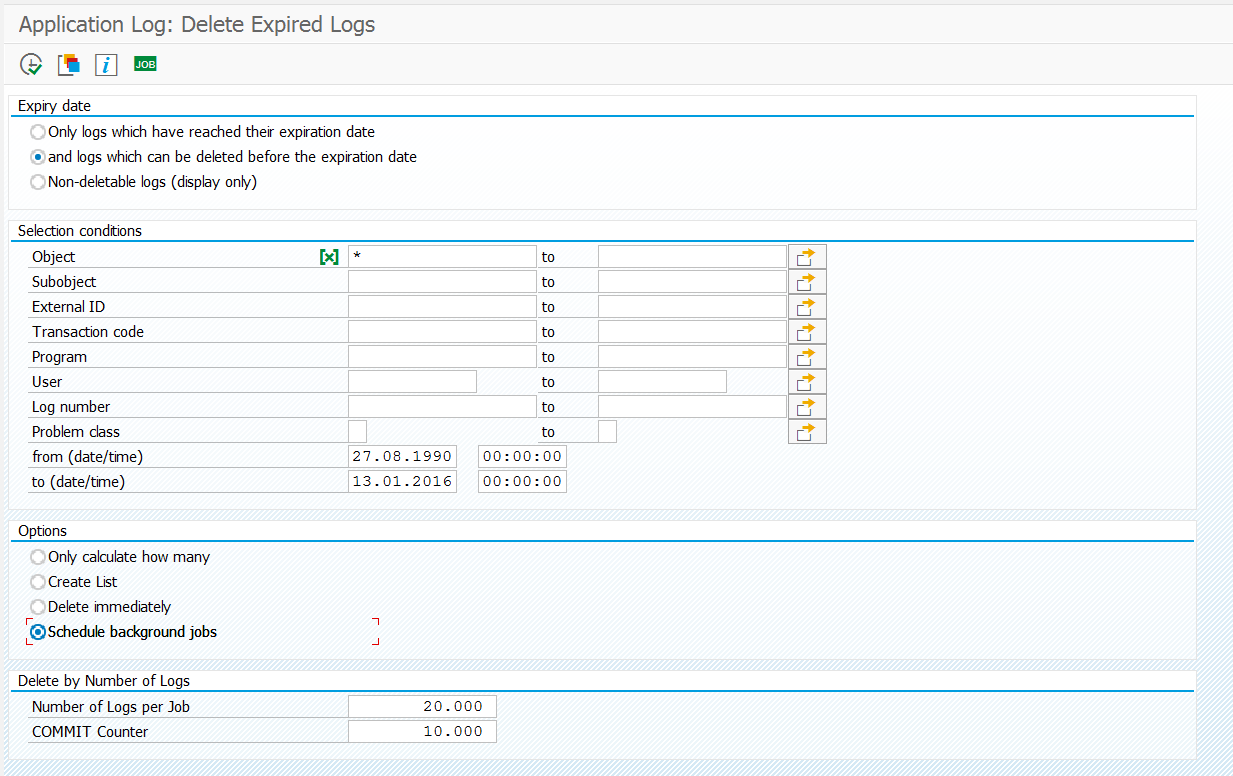
Downloading and implementing new versions of OSS notes
SAP regularly updates its own OSS notes. To check in your system if there are new updates for OSS notes relevant to you go to transaction SNOTE. Then choose “Goto -> SAP Note Browser ->Execute (F8)”, and then choose “Download Latest Version of SAP Notes” in the application toolbar. This will download all the latest versions. Check for the status “Obsolete version implemented” in the implementation state column.
Issues with OSS note downloads
In rare cases OSS note download and extractions might fail.
Please check these OSS notes:
- 1939285 – SCWN106 – SAP Note incomplete in transaction SNOTE or SPAU
- 2039673 – What are the differences between SAP Notes and SAP Knowledge Base Articles?
- 2880918 – SNOTE error: “Could not download the signed SAP Note” if a KBA will be selected for download
- 3191948 – Failed to extract SIGNATURE_<Note number>.SMF in path /usr/sap/trans/tmp/<Note number>_00.SAR
Activation of inactive objects after implementing OSS note
In rare cases after implementing an OSS note some of the ABAP objects are in an inactive state. To activate them, select the menu SAP note and then Activate SAP note manually.
Or you can run program SCWB_NOTE_ACTIVATE to activate the coding of the note:
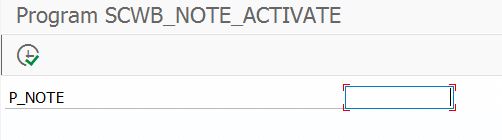
See OSS note 1882419 – How to correct syntax errors.
TCI: transport based correction instructions
Transport based correction instructions contain notes that are larger than normal OSS notes. This tool leverages the SPAM transaction to apply these large packages.
Relevant OSS notes:
Start with reading the PDF document attached to OSS note 2187425: TCI for customer. This contains the exact instructions to enable TCI based correction instructions.
The TCI only recently has a rollback function. Please check if you can update/patch to the version where the rollback works. See the PDF document in OSS note 2187425 on the undo function.
Applying TCI note
There are 2 ways to upload TCI note.
Basis way: you will need SPAM access rights and 000 actions are involved. Upload the TCI file in SPAM in client 000. Then apply the note via SNOTE in main client. The note tool will ask you to confirm to use the TCI mechanism.
ABAP way: you will need SPAM access rights. In transaction SNOTE use menu option Goto / Upload TCI. After uploading the file, choose Decompress. Now apply the note via SNOTE. The note tool will ask you to confirm to use the TCI mechanism.
During the implementation, it can be that you are forced to delete all BI queues.
Transporting obsolete TCI packages
When you upgraded earlier to S4HANA or other recent version, some of the TCI notes might be obsolete. There is an issue moving this through the landscape. Read and apply the solution from OSS note 3116396 – How to Adjust Obsolete TCI Notes in Downstream Systems for the fix.
TCI notes bug fixes
Bug fixes for TCI notes:
DDIC objects
For enabling de-implementation of DDIC objects apply oss note 2840923 – SNOTE: Enable De-implementation of DDIC Correction Instructions.
Digitally signed oss notes
For digitally signed oss notes see the special blog.
KBA notes
Some notes don’t contain coding updates, but are KBA’s: Knowledge Base Articles. You have to read the note which contains manual instructions or explanation in detail.

Finding OSS notes
Tools for finding OSS notes:
- ANST (advanced notes search tool): see blog
- ANST for web applications and FIORI: see blog
- Notes for error messages: see blog
- Short dump analysis: see blog
Special note programs
For special use cases SAP has special programs to check for recent OSS notes.
Use cases:
- SAP Screen Personas, run transaction /PERSONAS/HEALTH. See blog.
- SLT DMIS plug in, per use case different program. See blog.
| Scenario | Report name |
| Object Based Transformation (OBT) | CNV_NOTE_ANALYZER_OBT |
| ABAP Integration for SAP Data Intelligence (DI) | CNV_NOTE_ANALYZER_DI |
| S4HANA Migration Cockpit (MC) | CNV_NOTE_ANALYZER_MC_EXT |
| SAP Landscape Transformation (SLT) Replication Server | CNV_NOTE_ANALYZER_SLT |
| Near Zero Downtime Technology (NZDT) | CNV_NOTE_ANALYZER_NZDT |
Being notified upon OSS note updates
If you want to be notified when a certain OSS note receives an update, follow the instructions as described in OSS note 2478289 – How to set up notifications for SAP Notes and/or KBAs with Expert Search filters.
SNOTE revamp
In newer netweaver versions SNOTE is revamped. You can apply this version earlier if you want to use it. Read more on the SNOTE revamp in this blog.
Applying notes in shadow during upgrade
In rare cases you might need to apply and OSS note in the shadow system during a system upgrade. Basis team will usually use the SUM tool. Applying notes to shadow during upgrade can be needed to solve upgrade stopping bugs.
Always handle with care. If you are not experienced with upgrades, let a senior handle it.
The procedure to do this is described in OSS note 2207944 – How to implement a SAP note during System update using SUM (ABAP only).
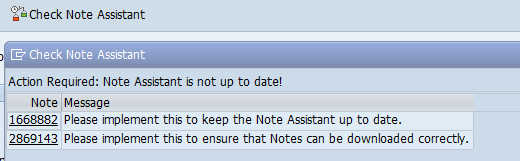
Bug fixes for SNOTE
SNOTE itself might have issues. Use the button Check Note Assistant to see if any new notes or note updates of generic SNOTE notes are needed:
How to find in which transport and OSS note is stored?
Follow the instructions in this blog. Summary: go to the SE03 transaction and choose “Find Objects in Requests/Tasks”. Enter R3TR NOTE object and your note number with leading zeros up to 10 chars. Select Modifiable and/or Released statuses according to your needs.