This blog will focus on technical clean up for SAP solution manager.
Questions that will be answered are:
How can I reduce size of fast growing tables in SAP solution manager?
Which functions of SAP solution manager are in use or were in use?
SAP Readiness check for Cloud ALM
SAP Cloud ALM will replace SAP solution manager. You can run the SAP Readiness check for Cloud ALM to determine which functions of solution manager you use or were in use in the past.
Technical clean up general
SAP solution manager is a netweaver system which also used BI functions. For the general tables read the Technical clean up blog and for the BI parts, the BI clean up blog.
If you set up the monitoring in the past, but are not using it, best to switch it off. If you are actively using it, consider moving it to SAP Focused Run, which is far superior. More on Focused Run in this blog series.
SAP BI can be used in BI itself, but BI is more available than you think: embedded BI in S4HANA, inside SCM, inside SAP solution manager, etc.
Also for BI systems a technical clean up of data might be required when the data volume becomes too high. For other clean up read this blog on technical clean up.
Questions that will be answered in this blog are:
How can I do a housekeeping on my BI system using a task list?
How can I execute a technical clean up of old BI technical data?
BI housekeeping task list
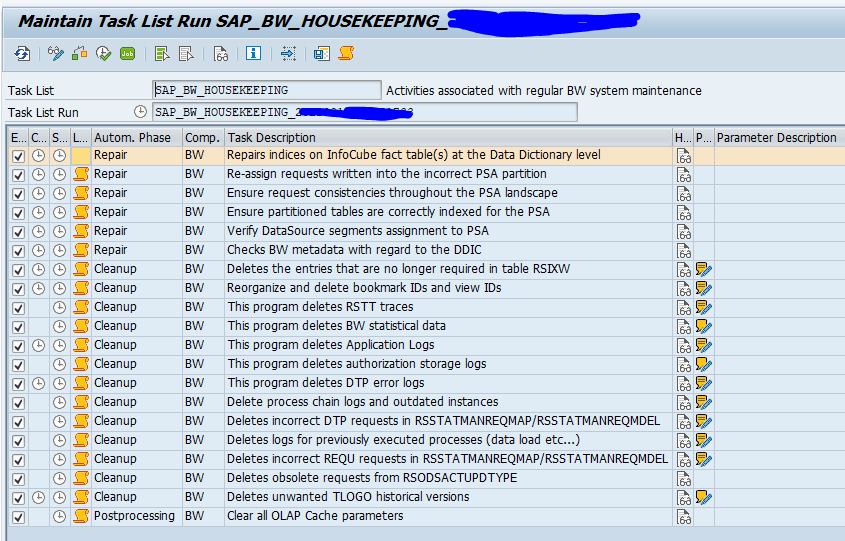
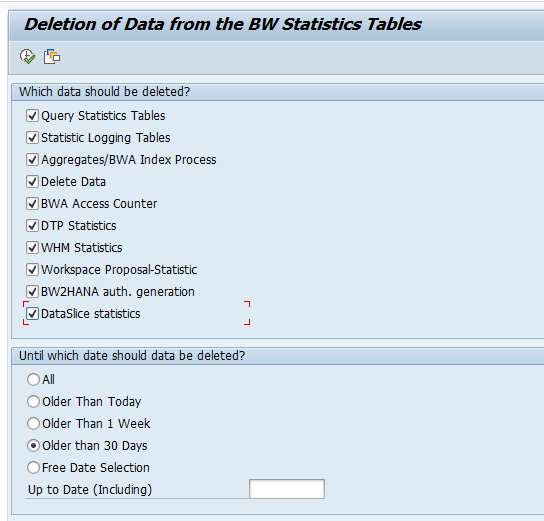
Go to transaction STC01 and start the SAP_BW_HOUSEKEEPING task list. Select all cleanups you want to perform. Select in the variants the retention times and dates. When done, start the task list (best to do in background mode):
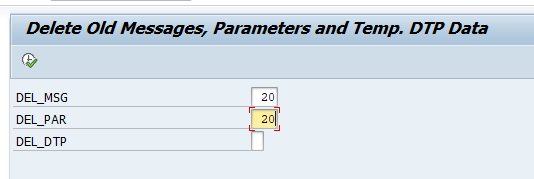
For Clean up of tables RSBATCHDATA and RSBATCHCTRL, you can use program RSBATCH_DEL_MSG_PARM_DTPTEMP (transaction RSBATCH):
Parameters: DEL_MSG to delete all records older than XXX (From 000 to 999) days (M-Records). DEL_PAR to delete all records older than XXX (From 000 to 999) days (R and P-Records). DEL_DTP has no meaning.
This blog will explain the maintenance of logical file names.
Questions that will be answered in this blog are:
Why use logical file names?
How to setup logical paths and logical file names?
Which variables can be used in logical file names and logical paths?
What is new in transaction SFILE?
Why use logical file name?
The use of a logical file name in any ABAP keeps the location and name name of the file constant from a logical function perspective. The actual implementation of the file location can then be maintained by the basis team. If they want to move files around, they can do so, as long as they also update the logical files. Also this way an ABAP developer does not need to worry in case of any OS switch (for example from Windows to Linux).
The names are the same on development, QA and production system. The basis team can choose to have different file structures on each system. For example by including the system ID in the folder name.
Maintaining logical file path
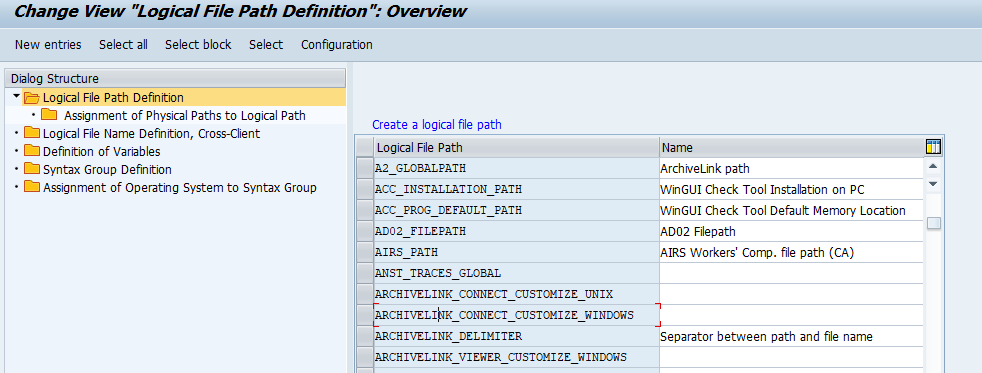
To maintain logical file names, start transaction FILE:
With new entries, you can add new logical file path.
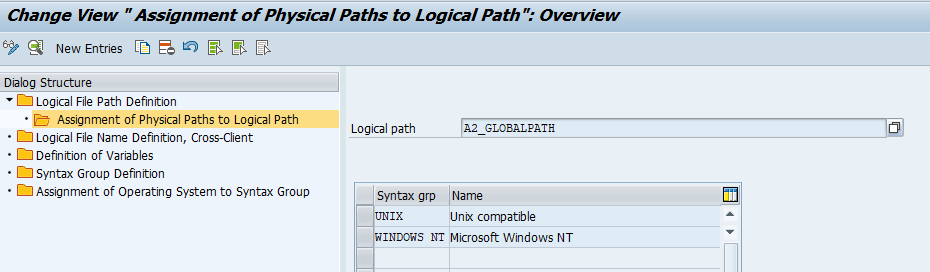
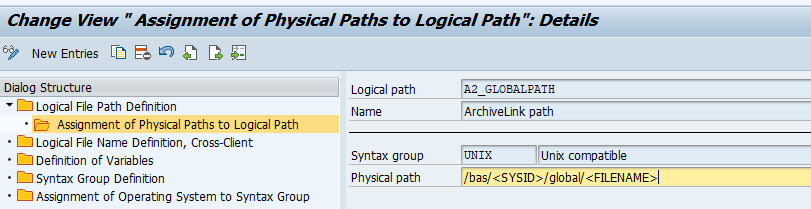
We will use A2_GLOBALPATH here as example. Select the entry and click on Assignment of physical path to logical path:
Select the operating system to see the details:
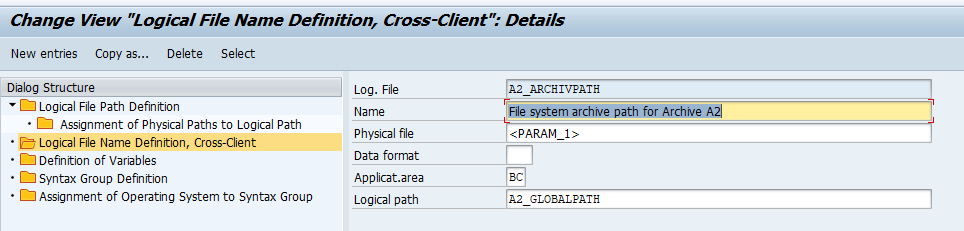
Logical file names
Logical file names are also maintained with transaction FILE:
Parameters in naming
The following parameters can be used in the naming conventions:
Parameter
Meaning
<OPSYS>
Operating system in function module parameter
<INSTANCE>
Application Instance
<SYSID>
Application name in accordance with system field SY-SYSID.
<DBSYS>
Database system in accordance with system field SY-DBSYS
<SAPRL>
Release in accordance with system field SY-SAPRL
<HOST>
Host name in accordance with system field SY-HOST
<CLIENT>
Client in accordance with system field SY-MANDT
<LANGUAGE>
Logon language in accordance with system field SY-LANGU
<DATE>
Date in accordance with system field SY-DATUM
<YEAR>
Year in accordance with system field SY-DATUM, four characters
<SYEAR>
Year in accordance with system field SY-DATUM, two characters
<MONTH>
Month in accordance with system field SY-DATUM
<DAY>
Day in accordance with system field SY-DATUM
<WEEKDAY>
Weekday in accordance with system field SY-FDAYW
<TIME>
Time in accordance with system field SY-UZEIT
<STIME>
Hour and minute in accordance with system field SY-UZEIT
<HOUR>
Hour in accordance with system field SY-UZEIT
<MINUTE>
Minute in accordance with system field SY-UZEIT
<SECOND>
Seconds in accordance with system field SY-UZEIT
<PARAM_1>
External parameter 1 passed in function call
<PARAM_2>
External parameter 2 passed in function call
<PARAM_3>
External parameter 3 passed in function call
<P=name>
Value of a profile parameter in the current system
<V=name>
Value of a variable in the variable table
<F=name>
Return value of a function module
Transaction SFILE
Transaction SFILE is a new maintenance transaction. It is available as of S4HANA 1610. The main functions are the same as FILE. Main new function is the mass download and upload of definitions.
When executing data archiving you have to be acting careful. The data archiving write and delete processes can be consuming a lot of CPU power from the database. Also, if you are not careful you might, by accident, claim all background processes. This blog will explain how to limit the amount of batch jobs used for data archiving. The data archiving run process itself is described in this blog.
Questions that will be answered in this blog are:
How can I limit the amount of deletion jobs?
How can I restrict the archiving jobs to run on a specific application server only?
Limit amount of deletion jobs
When the write run of data archiving is finished, this can have delivered many files. If you are not careful with the deletion, you select all files and each file will start a deletion run. This will consume a lot of CPU power on database level, since the deletion run will fire many DELETE statements to the database in rapid sequence. Also you might consume all batch jobs, leaving no room for any business batch job.
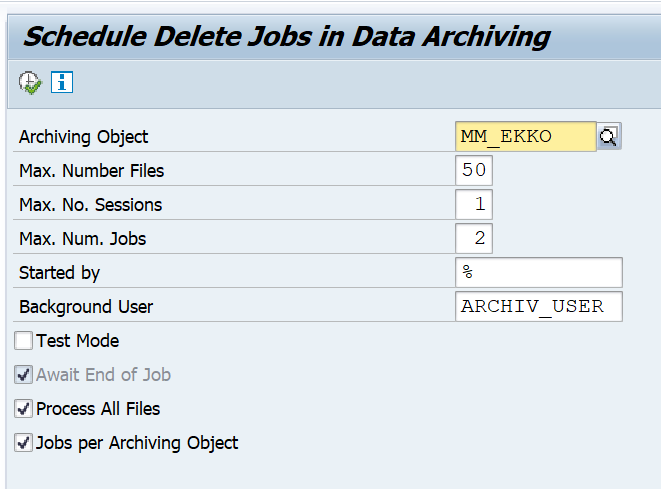
In stead of running the deletion from SARA, you can also run the deletion via program RSARCHD:
With this example, MM_EKKO files will be deleted. Maximum of 50 files from 1 archiving run will be processed, with a maximum of 2 deletion batch jobs running at the same time.
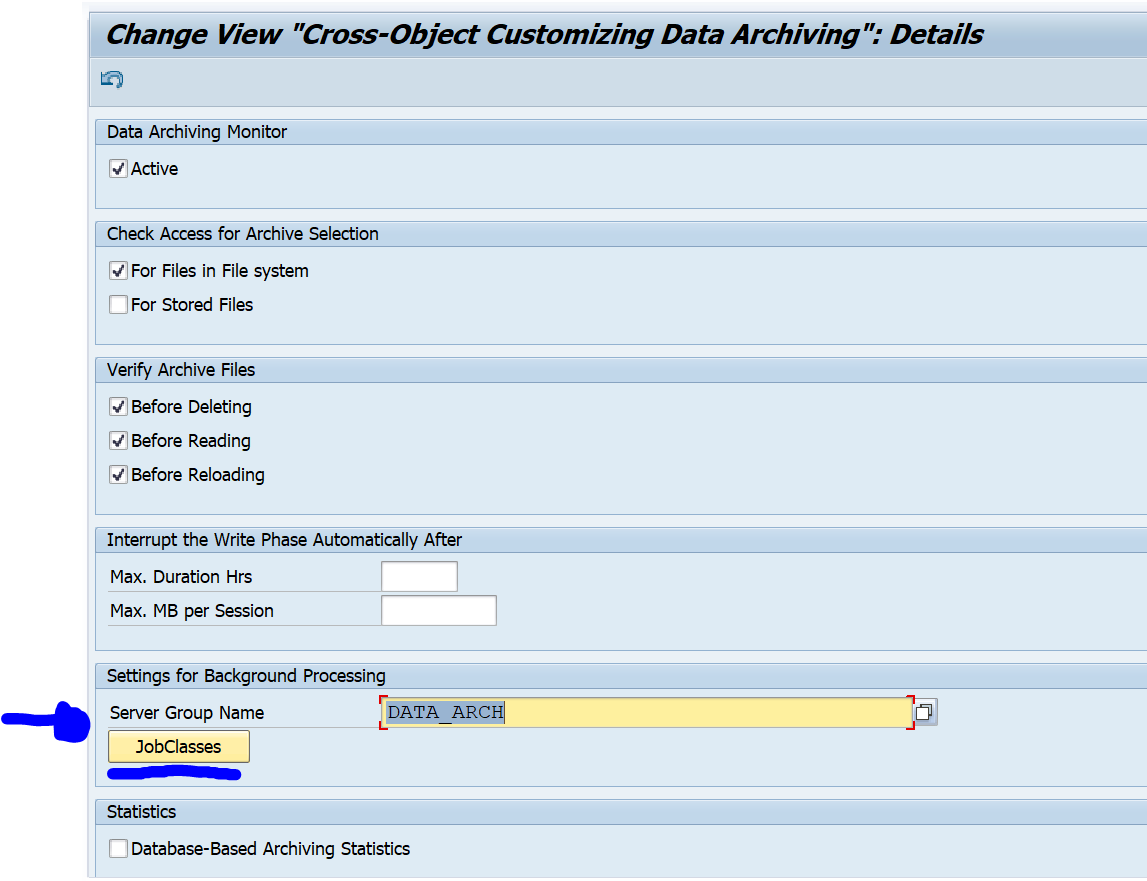
General application server restrictions via batch job server group
In SM61 you can setup a special batch job server group. Here can assign a single application server for you data archiving batch job processing. We assume here you created a group called DATA_ARCH.
In SARA you can now goto the general data archiving settings:
Now you can link the batch job server group:
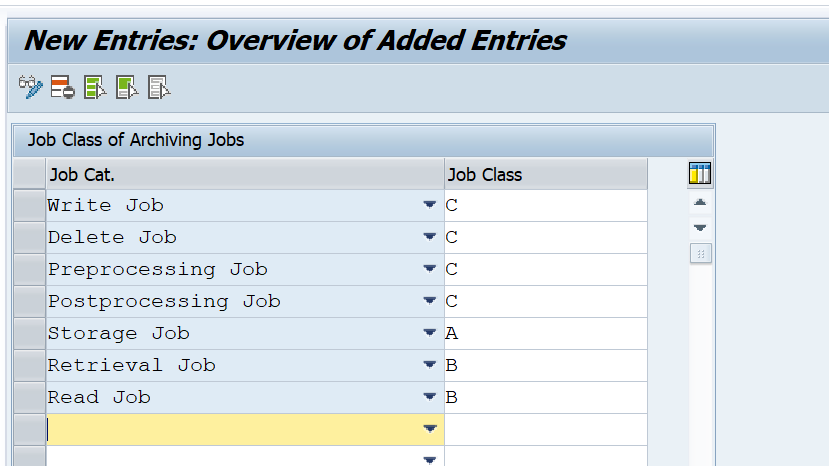
With the button JobClasses you can specify the job priorities per data archiving function:
A = high priority, C = low priority. The above screen shot is an example.
Some archiving object use the AIS (archiving information system) to enable the end user a quick retrieval of archiving information. This note will give warning before start of deletion if the AIS is note active for the object: 2624077 – Starting delete jobs: Check for active info structures.
This blog addresses the main challenge in SAP data archiving for functional object: the discussions with the business.
This blog will give answers to the following questions:
When to start data archiving discussion with the business?
How to come to good retention periods?
What are arguments for not archiving certain data?
Data archiving discussion with the business
Unlike technical data deletion, functional data archiving cannot be done without proper business discussion and approval.
Depending on your business several aspects for data are important:
Auditing and Sox needs
Tax and legal retention periods
Product data requirement
And so on…..
Here are some rules of thumb you can use before considering to start up the business discussions about archiving:
Rule of thumb 1: the system is pretty new. At least wait 3 years to get an insight into which tables are growing fast and are worth to investigate for data archiving.
Rule of thumb 2: if your system is growing slowly, but the infrastructure capabilities grow faster: only perform technical clean up and don't even start functional data archiving.
Rule of thumb 3: if you are on HANA: use NSE (Native Storage Extension). NSE does not require too much work, it is only technical and it does not require much business discussions. Data retrieval from end user perspective is transparent.
Data analysis before starting the discussion
If your system is growing fast and/or you are getting performance complaints, then you need to do proper data analysis before starting any business discussion.
Start with proper analysis on the data. Use the TAANA tool to get insights into the data: how is the distribution of data per document type, per year, per plant/company code etc. If you want to propose retention period of let’s say 5 years, you can use the TAANA results to show what percentage of data you can move out of the database.
Secondly: if you have an idea on which data you want to archive, first execute a trial run on a recent production copy. There might be functional blocks that prevent you from archiving data (like not closed documents).
Third important factor is the ease of data retrieval. Some object have a nice simple data retrieval function, and some are really terrible. If the retrieval is good, the business will more easily accept a shorter retention period. Read more on technical data retrieval in this blog.
As last step you can start the business case: how much data will be saved (and how much money hence will be save) and how much performance would be gain. And how much time is needed to be invested for setting up, checking (testing!) and running the data archiving runs.
In practice data archiving business case is only present in very large systems of 5 TB and larger. This sizing tipping point changes in time as hardware gets cheaper and hourly manpower costs go up.
The discussion itself
Take sufficient time for the discussions. It is not uncommon that archiving discussions take over a year to complete. The better you are prepared, the easier the discussion. It also helps to have a few real performance pain points to get solved via data archiving. There is normally a business owner for this pain point who can help push data archiving. Or when your business needs to buy extra HANA licenses. Data archiving and/or NSE can avoid these costs.
This blog will explain how to execute a data archiving run.
Questions that will be answered in this blog are:
Which settings do I need to make or check before data archiving run?
How to perform the data archiving run?
How to validate the data archiving run?
How to retrieve that archived data?
This blog assumes you have finished the basic technical data archiving setup as described in this blog. It also assumes you have made agreements with your business on the retention periods. For more information and tips on discussions with the business teams on data archiving, read this blog.
If you are looking for specific functional data archiving runs:
Functional data archiving example: purchase requisitions
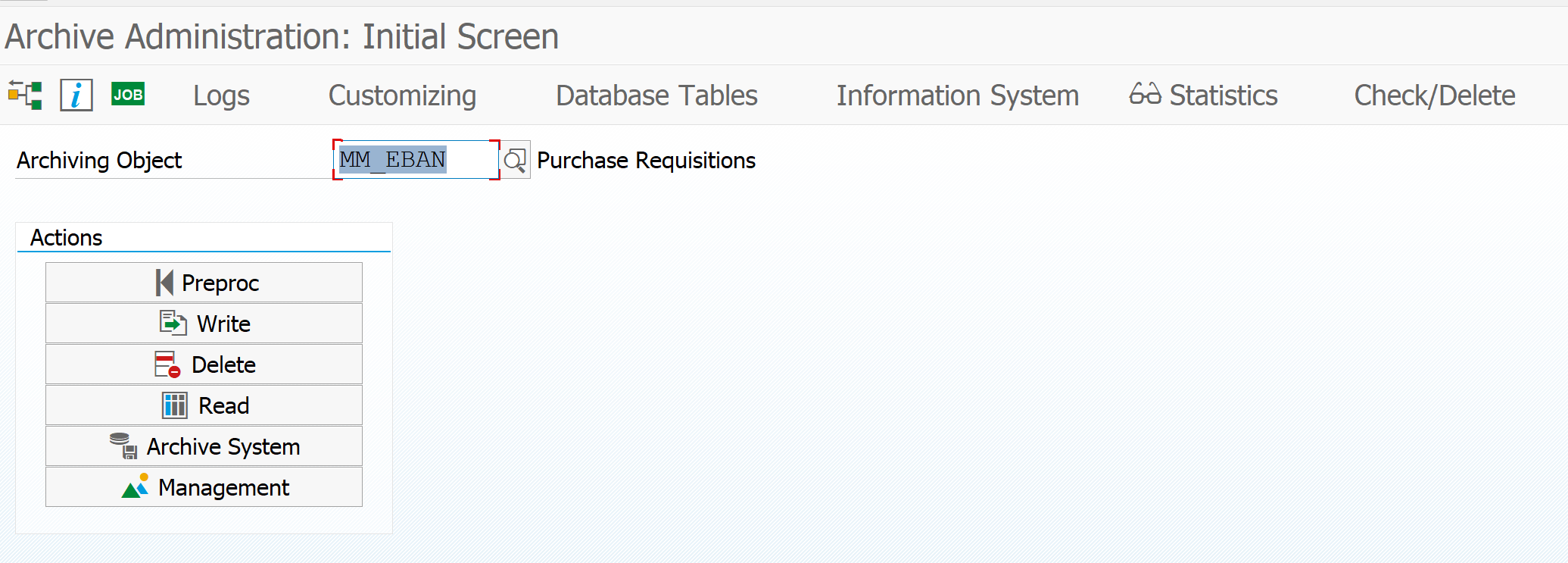
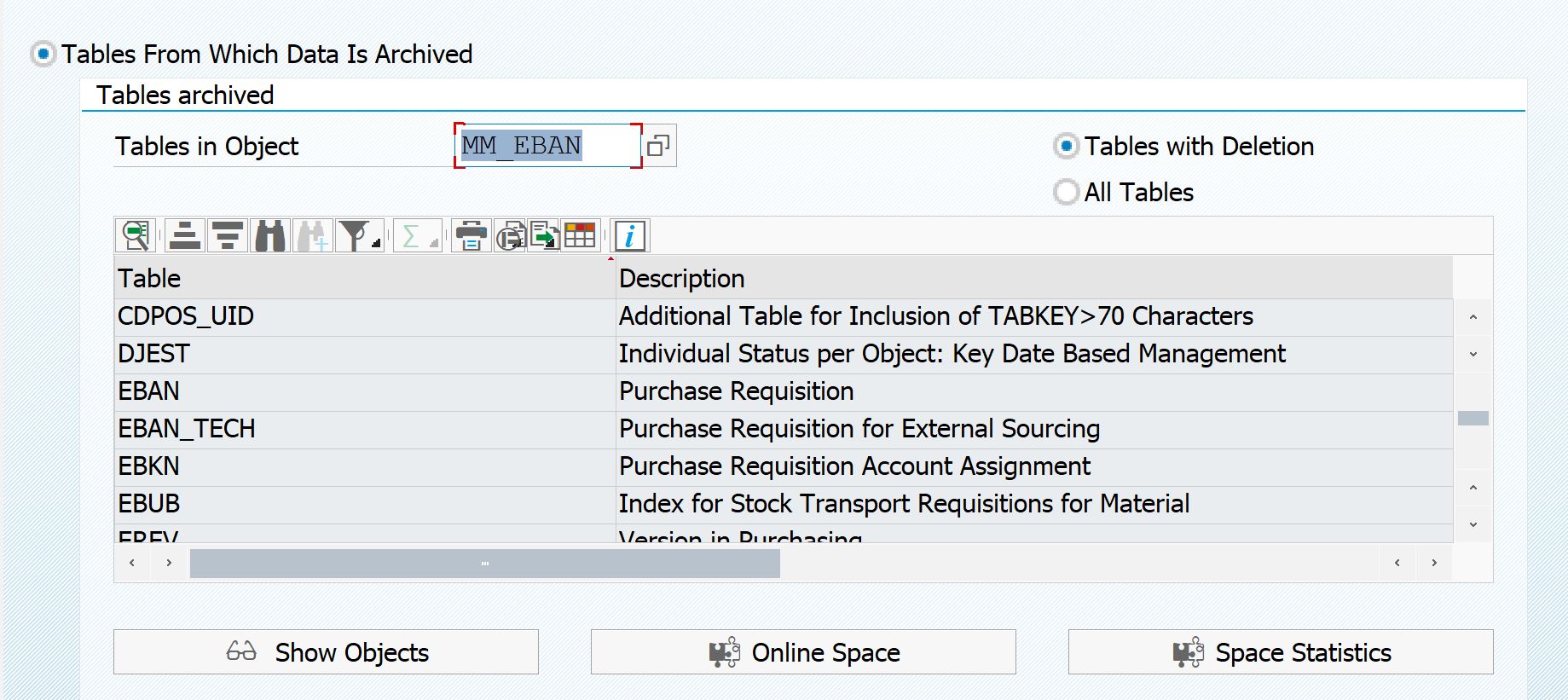
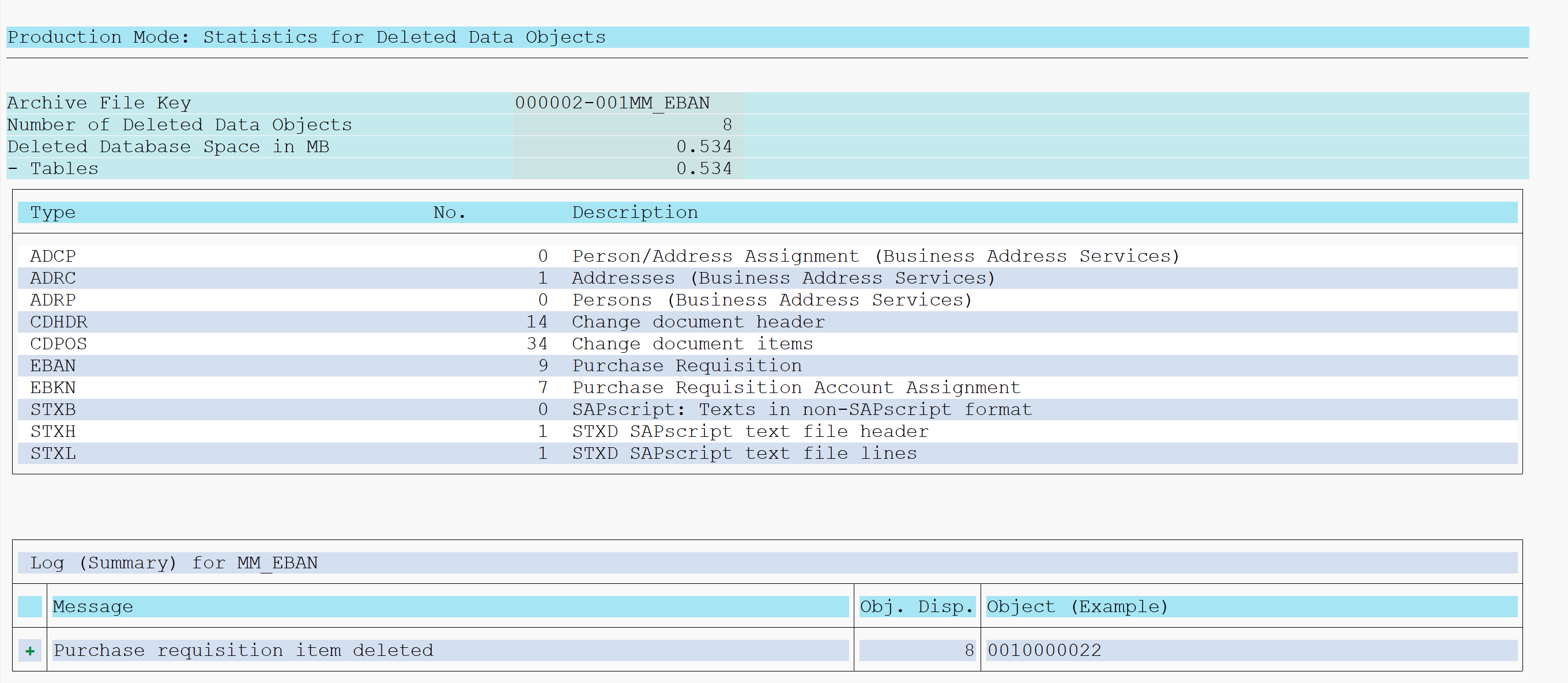
To explain the functional data archiving we will use Purchase Requisitions as example. Technical object name is MM_EBAN.
To see which tables are archived hit the Database Tables button. Here you can see the list of tables from which data potentially be archived:
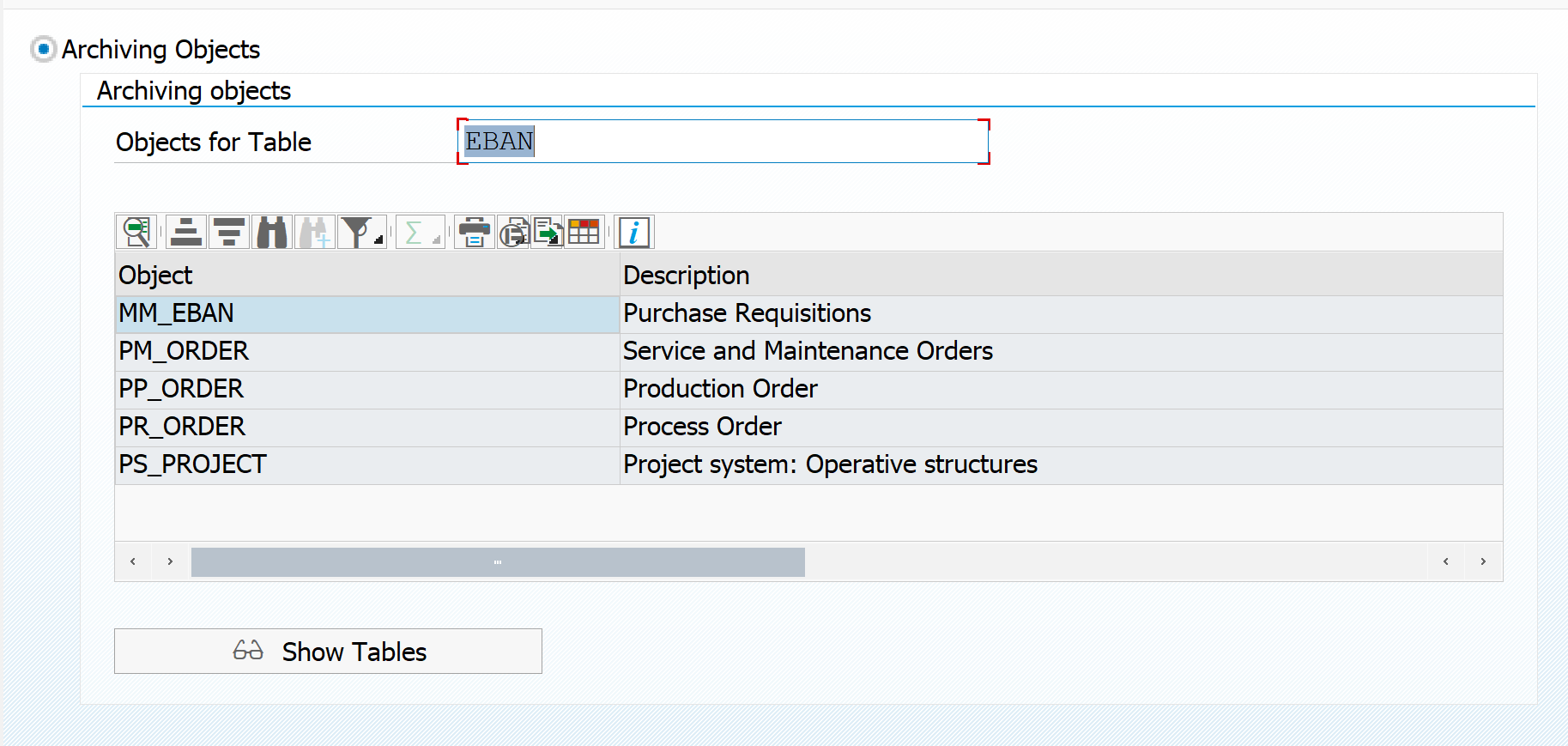
If you want to see the other way around, which table is used in archiving objects, do put in the table as entry point, to retrieve list of archiving objects. In this example archiving objects that delete from table EBAN:
Dependency of objects
By clicking the top left button on the archiving object you get the archiving dependency view. For MM_EBAN this is pretty simple: it has no dependencies.
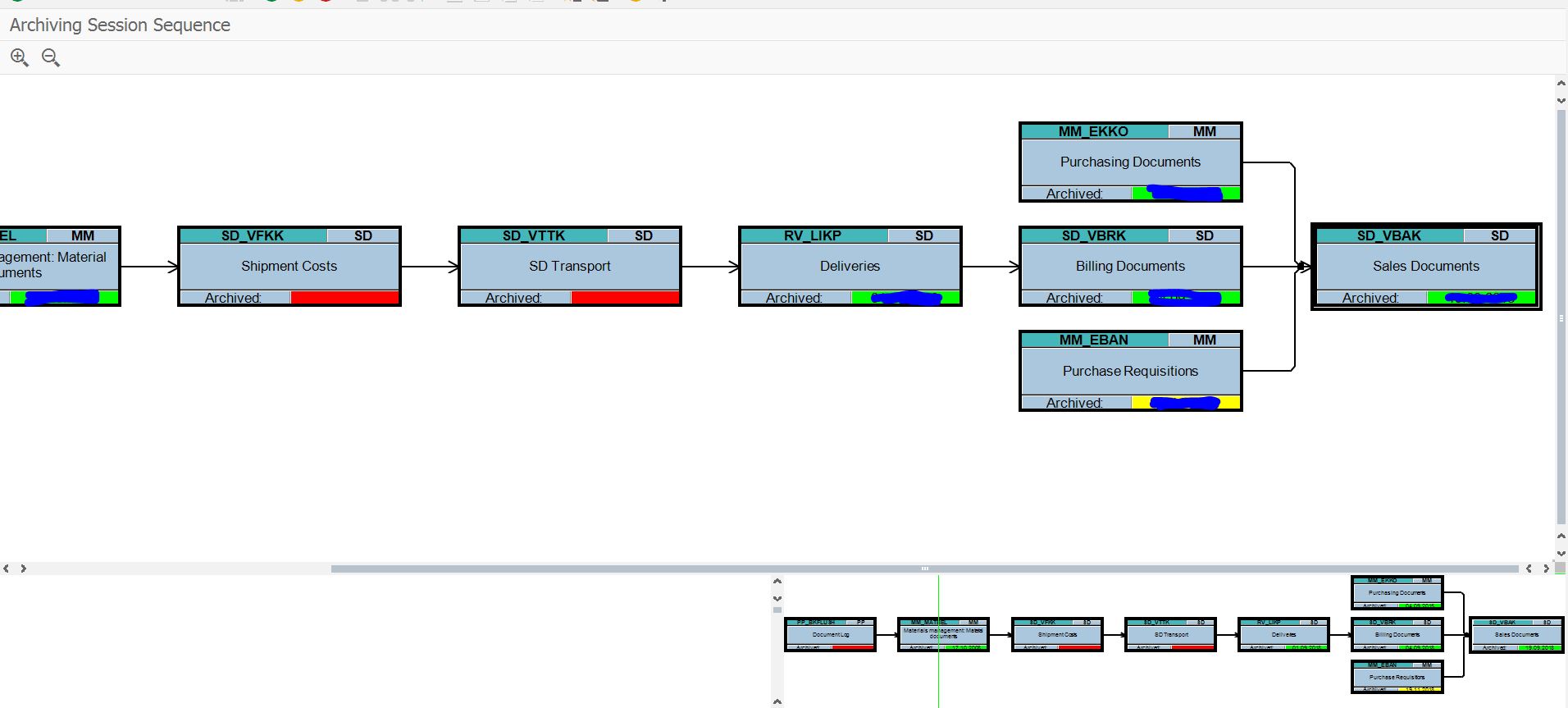
As example for dependencies this is the overview for sales orders (SD_VBAK):
Here you can see that before you can archive sales orders, you should archive the billing documents first. And for the billing documents, you should archive the deliveries first.
Functional archiving settings
First we have to make or check the object specific functional archiving settings.
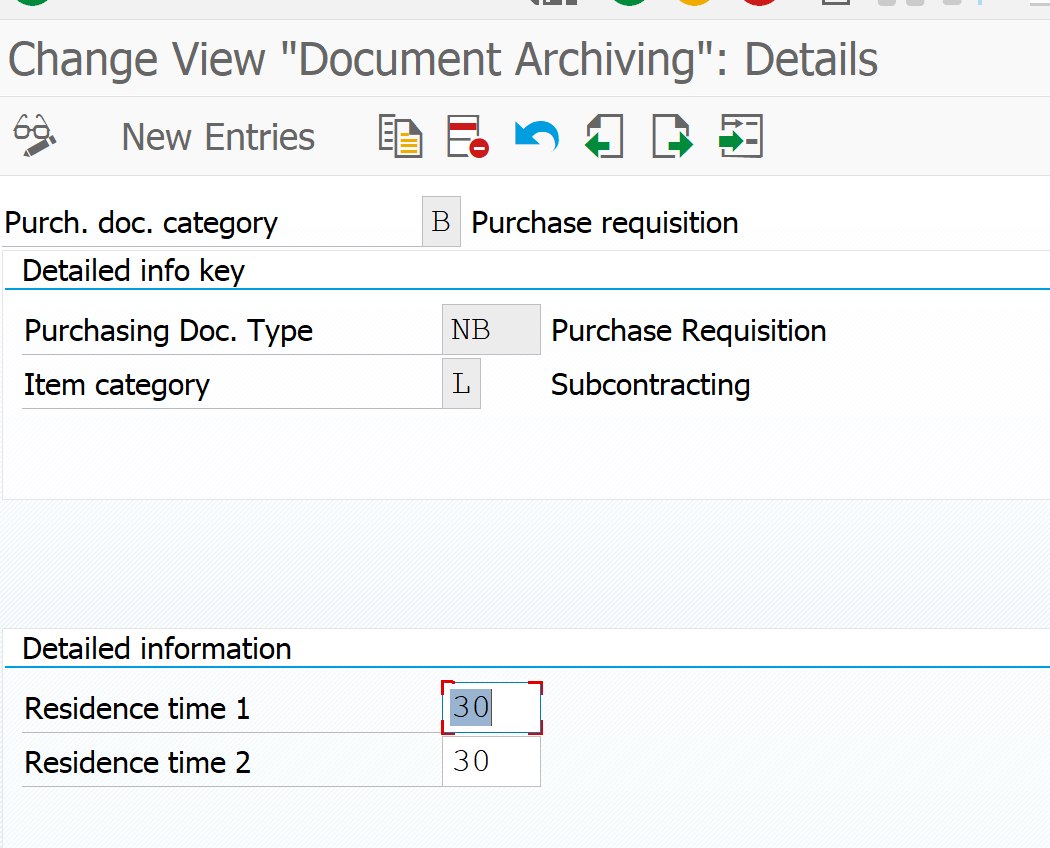
In the case of purchase requisitions we have to set the retention periods per document type:
Pre-processing step
Some archive object have a pre-processing step. MM_EBAN has one as well. In this step data is selected and marked for archiving (many times by setting deletion flag or other indicator).
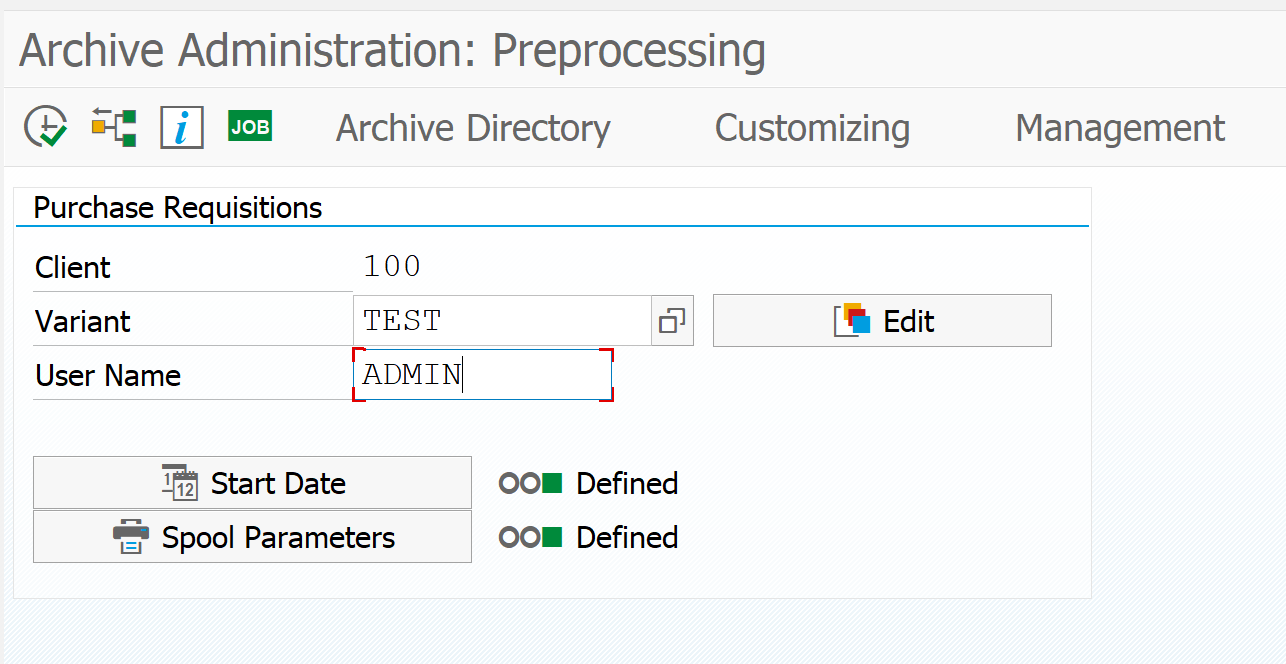
In the step create the variant (give it a useful name) by putting in the name and pressing Edit. On the next screen fill out your data select the log level. Go back to the first screen and select the start data and spool parameters. When both lights are green, hit the execute button. When you click the job log button you check for the results.
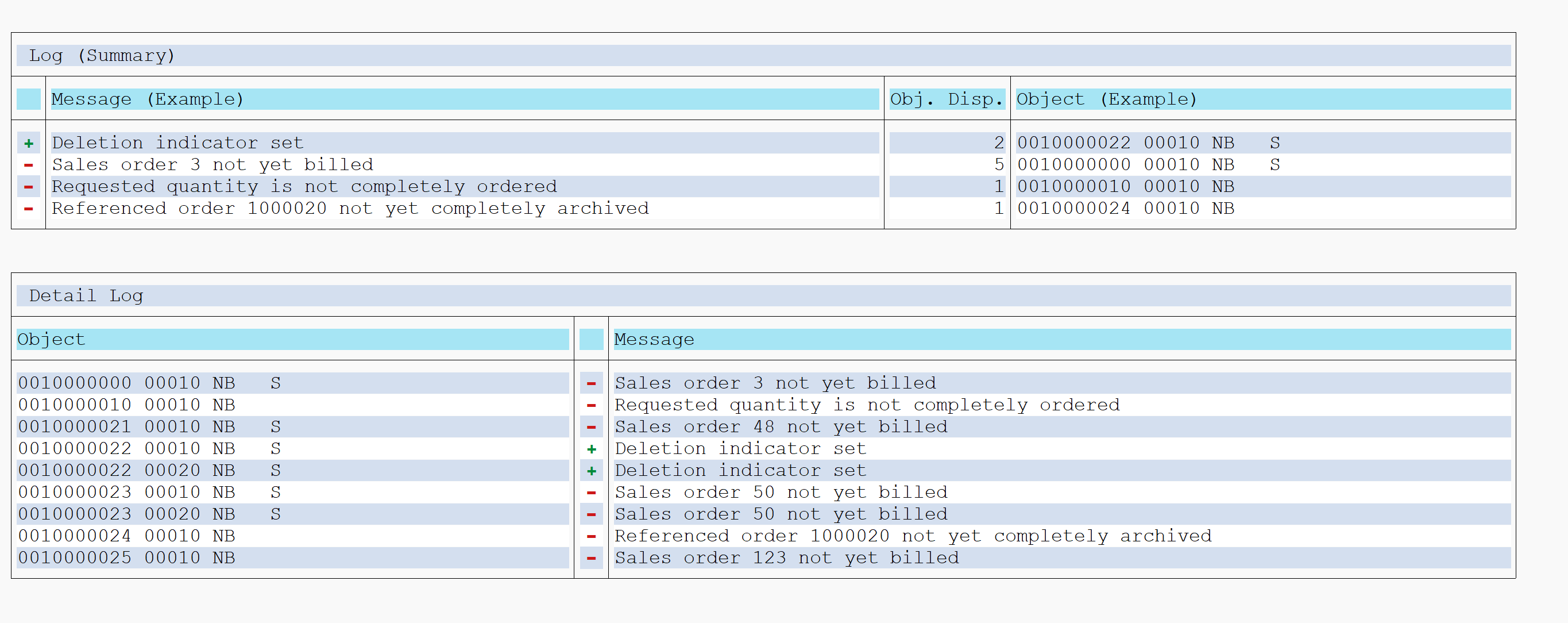
Example of result of pre-processing run:
As you can see not all selected data is archived. Transactions that are not completed from business point of view will not be flagged for archiving.
Write run
If you have done the pre-processing step, continue with the write step. Principle is the same: select the data and log level. Important in the write step is to correctly fill the Archiving Session Note with a useful text. This text is put as label on the archive file for later retrieval:
When done plan the job and execute. Result looks like:
Pending on your technical system settings the file will be stored automatically or you still need to do this manually.
Storage run
If you have setup the system to store files in content server, you first have to execute storage run. For more details see this dedicated blog.
Deletion run
Finally we can now start the deletion run: the actual clean up of old data happens now.
Select the data files you want to archive and start the run.
Word of care with deletion: please don't select too much files and subsection in one go. Each file sub section will result into a deletion job. The deletion will put significant load on the database, since it will be pushing out a lot of data. If you are not careful you will launch easily 20 or more heavy deletion jobs that run in parallel and that might severely decrease system performance.
Result of archiving deletion run:
Checking archive result
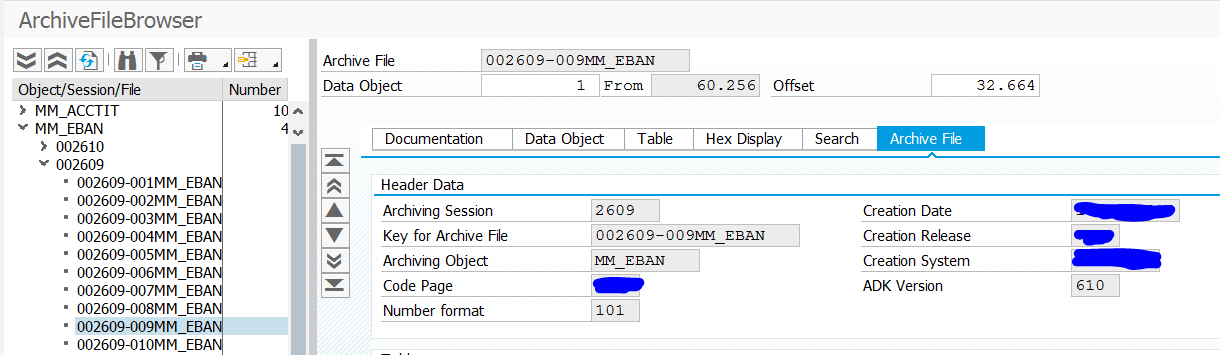
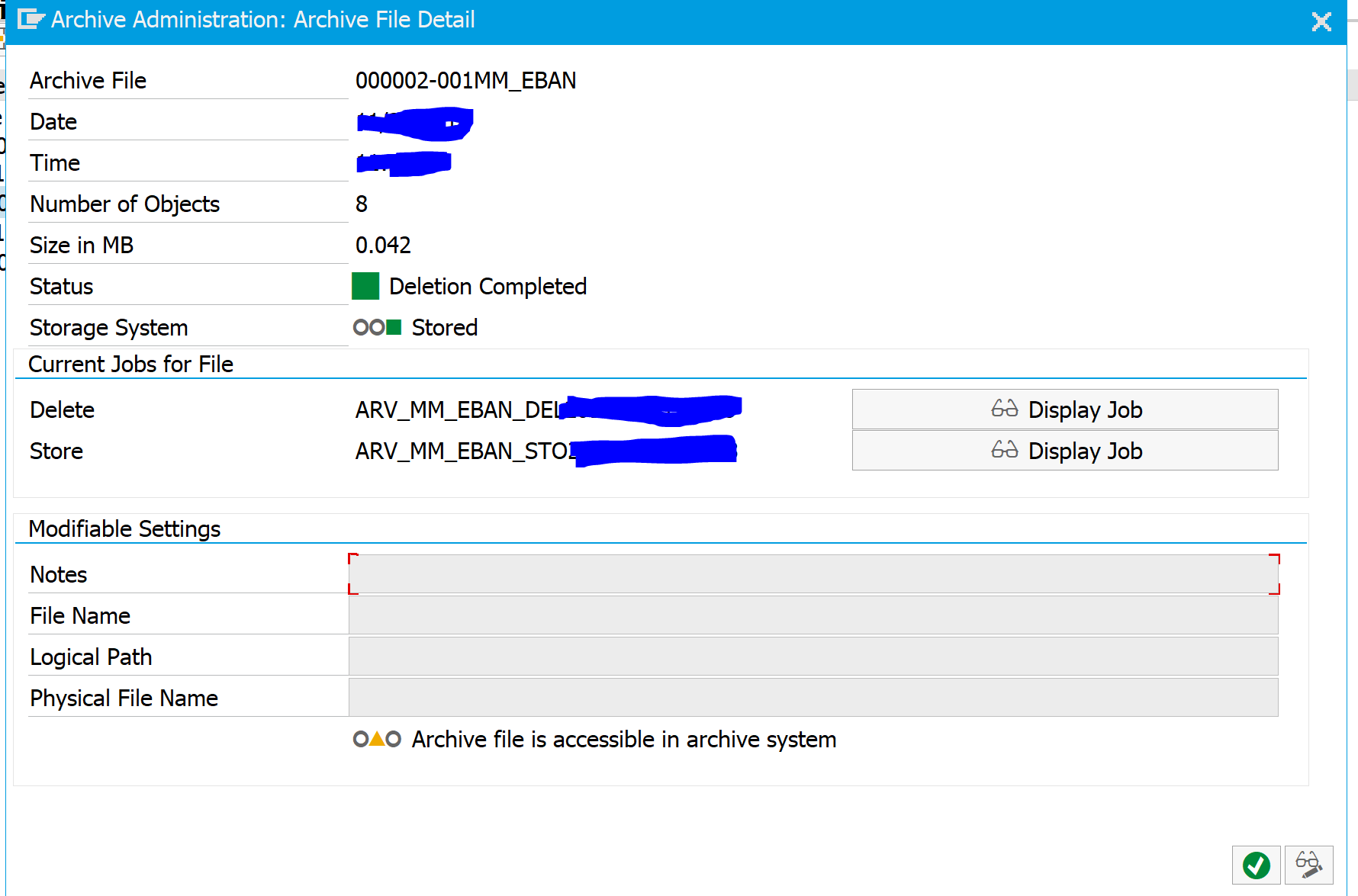
The result checking is possible by looking at the technical correctness of the archive file.
In the archiving object choose the Overview button. Then select the archive file you want to inspect. A correct file should like like this:
In the testing phases and first production runs, you also want to do record counting. A good way is to run the TAANA transaction for key tables you want to archive before the archiving and after the archiving. The difference should match the deletion counter on the write and deletion logs. If you find differences: check for bug fix OSS notes.
Data retrieval
Retrieving archived data is different per archived object. Some retrieval is nicely integrated into the normal transaction. Some require extra transaction to run. Some retrieval is via special program.
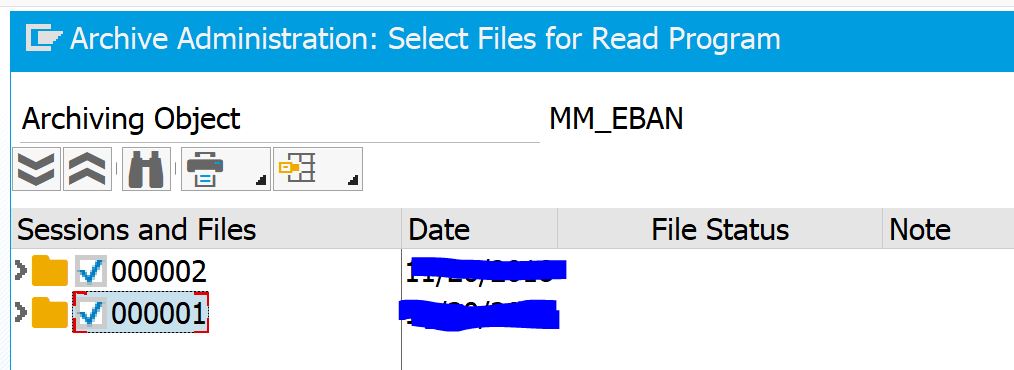
Data retrieval of purchase requisitions can be done via SARA and choosing the read option.
Here you first need to manually select the archive files to read from (see I did not give the note and regret it, since the file has no meaning now…):
Before starting to check the data archiving for an object, it is best to check and read the OSS notes for the pre-processing, write, delete and read programs. Apply the bug fix notes and read about certain aspects, before you have time-consuming effort to figure out you have a bug or a certain feature that is documented inside the notes.
Controlling amount of parallel batch jobs
The deletion phase of archiving can lead to uncontrolled amount of parallel batch jobs. See this dedicated blog on how you can control it.
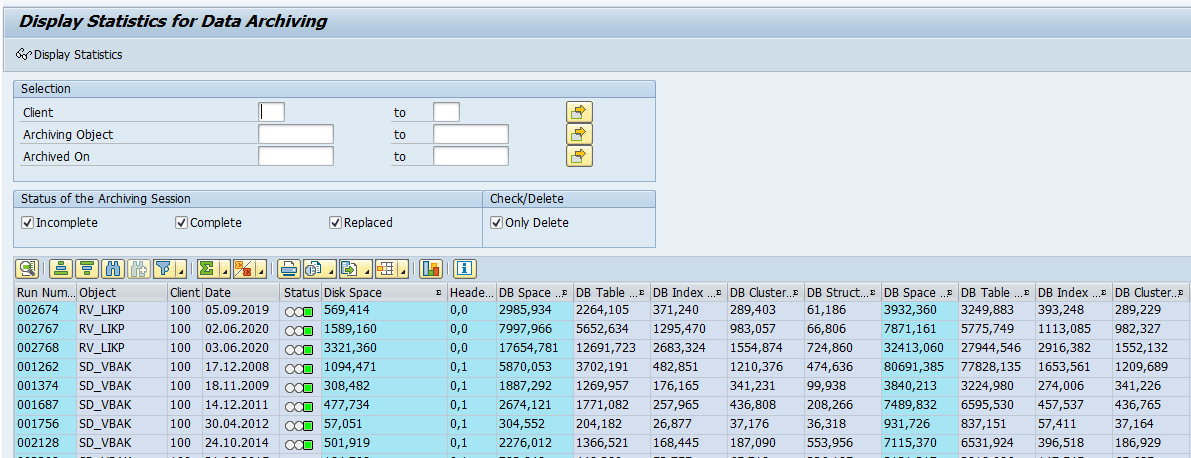
Data archiving run statistics
Transaction SAR_DA_STAT_ANALYSIS can be used to collect statistics on the data archiving runs:
FIORI app
If you are running recent version of S4HANA, you can also use a FIORI app for monitoring the data archiving runs. Read more in this dedicated blog.
This blog will explain the general technical setup to be performed for SAP data archiving.
Questions that will be answered in this blog are:
Which generic settings do I need to make for data archiving in the technology domain?
Why should I use a content server to store archive files?
For getting insights in what to archive, read this dedicated blog first.
Data archiving content server setup
For data archiving you can use the file system for storing the archive files. This you can do to perform initial testing. For productive use it is best to store the archive files in a content server. It will not be the first time an overzealous basis person in need for file storage deletes some old files in a directory called /archive…..
After you install the content server, set up in OAC0 the customizing for the content server to use it for Archivelink:
In this initial screen no object is selected. Now press the Customizing button.
Set the Cross-Client File Names/Paths to your needs. You can do that from this menu, or directly from the FILE transaction.
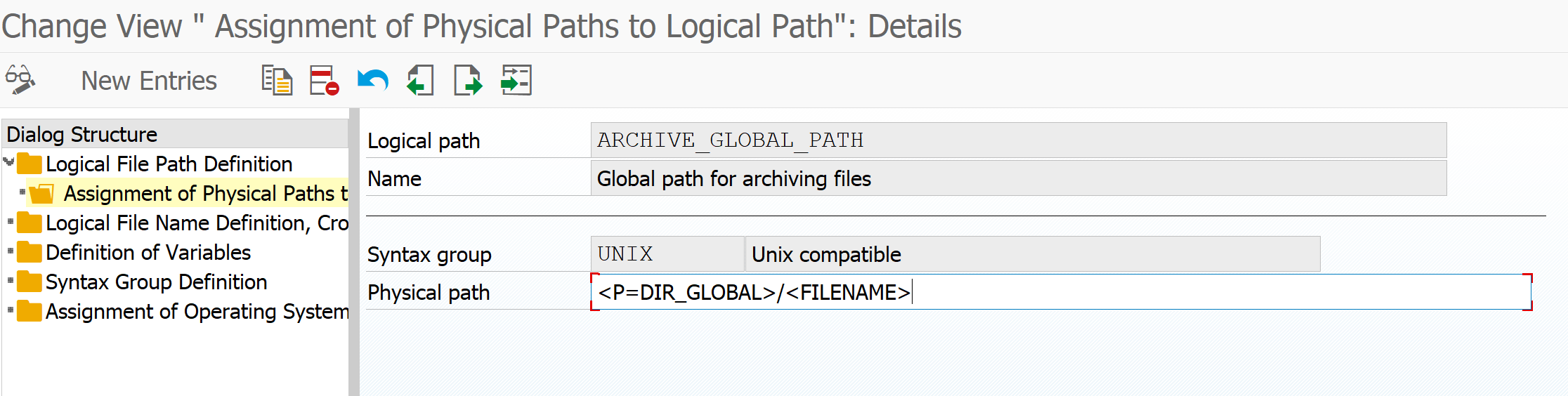
Set the physical path name to be used:
Even when you use content server the file will first be written to physical path for temporary storage.
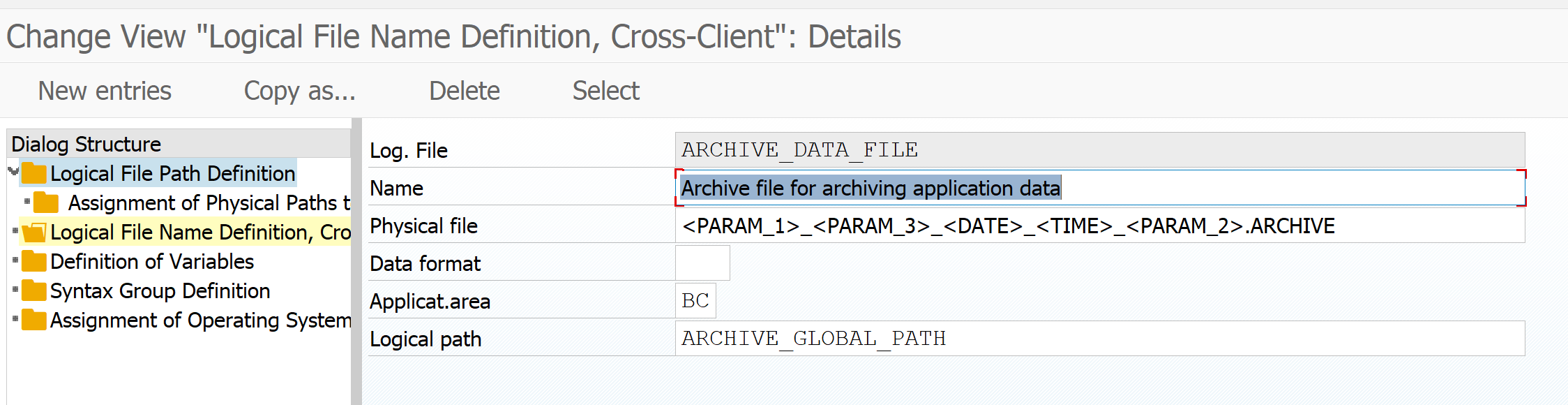
And check the archive file name:
Technical settings per archiving object
Per archiving object you can set the technical settings. Normally you keep settings the same per object. Only for very large installations with archiving or special needs, you might want to deviate.
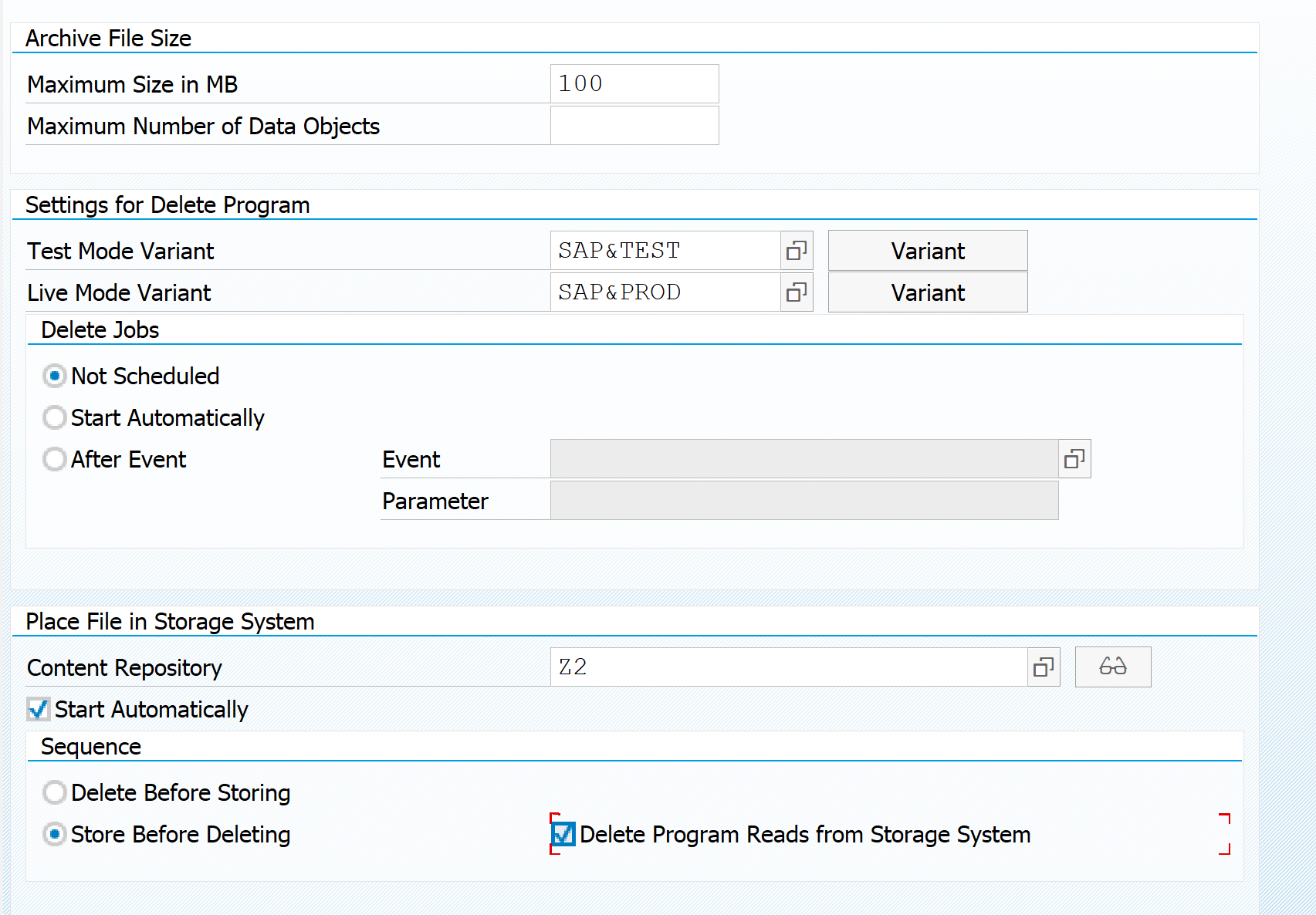
In the technical settings per data archiving object set the following:
Important settings to set:
Max size in MB or the max objects
Check the variants (some variants for production have still deliberately the test tick box as on: you have to change it)
Best to leave the delete jobs to Not scheduled (large archiving runs can create many files and many deletion jobs to kick in at the same time): best to do this manually in controlled way
Start storage automatically or manually is a choice for you
Best to store before deletion. This is the most conservative setting.
Best to delete only from storage system: if file is not stored properly in any way, deletion will not have. This is the most conservative setting.
Actual data archiving runs
How to execute the actual data archiving runs is explained in this dedicated blog.
This blog will explain how to setup print list archiving.
Questions that will be answered are:
What is use case of print list archiving?
How to setup print list archiving?
How to test print list archiving?
How to troubleshoot issues with print list archiving?
Goal of print list archiving
The business sometimes needs to store report output for a longer period of time. They can print the information and put it in their archive. This leads to a big physical archive.
You can also give the business the option store their output electronically in the SAP content server.
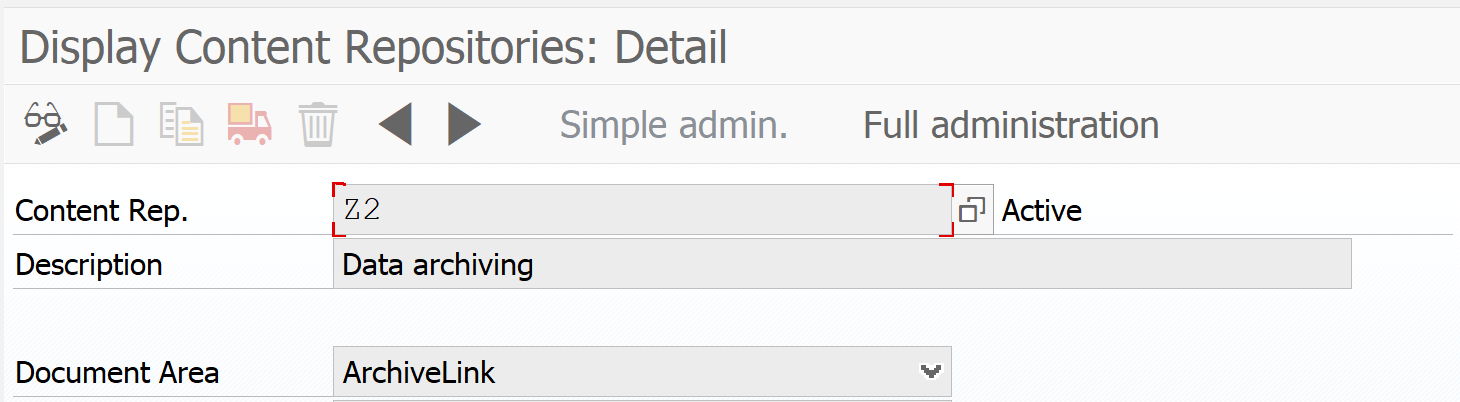
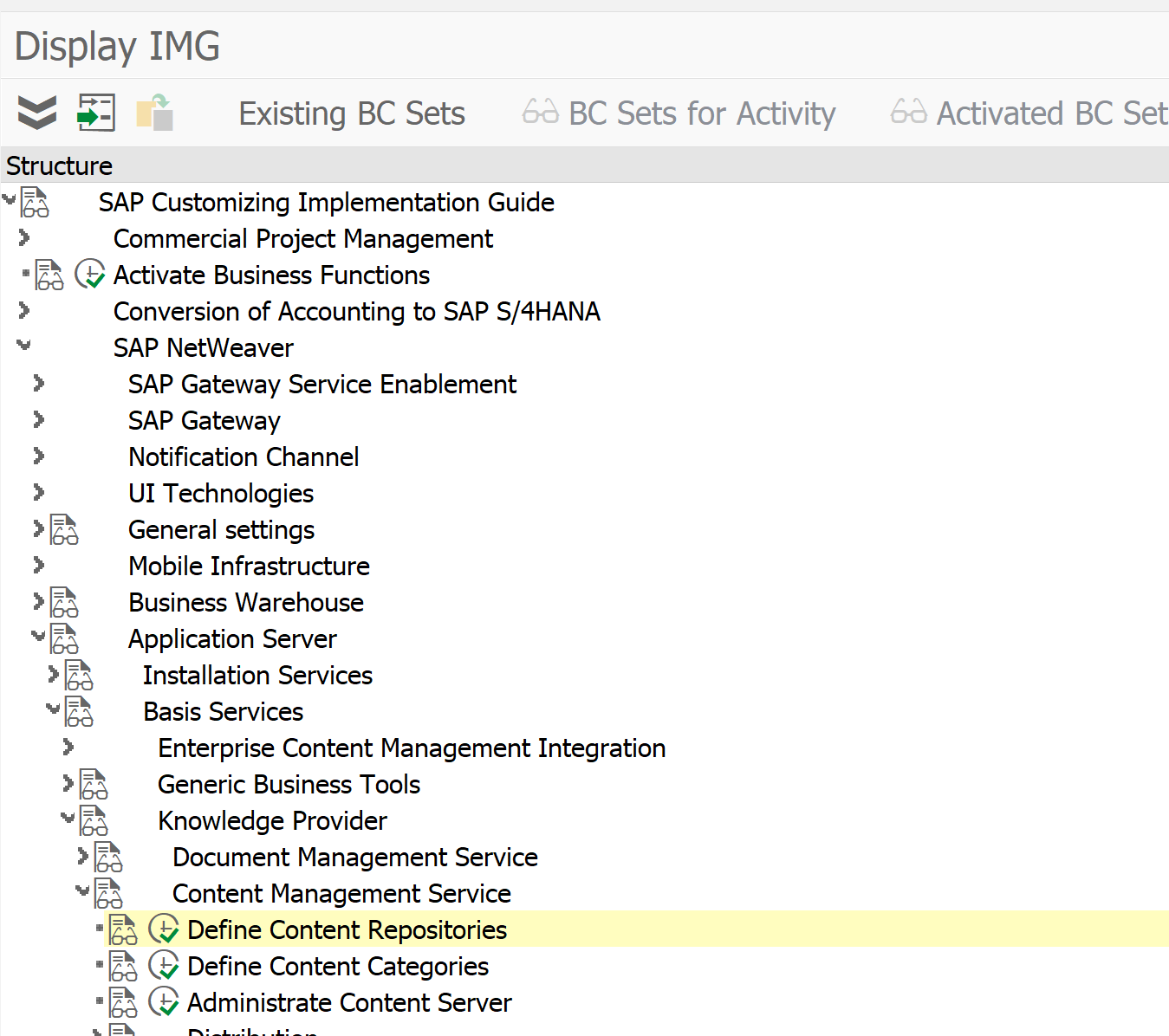
Set up or check content repository
First check which content repository you want to use to store the print lists. The type of content repository must be “ARCHLINK”. Menu path in customizing is as follows:
Or you can go there directly with transaction OAC0.
Content repository A2 is default present in the system and is used in the example below. A2 is pointing towards the SAP database for storage. For productive use a SAP content server in stead of SAP database.
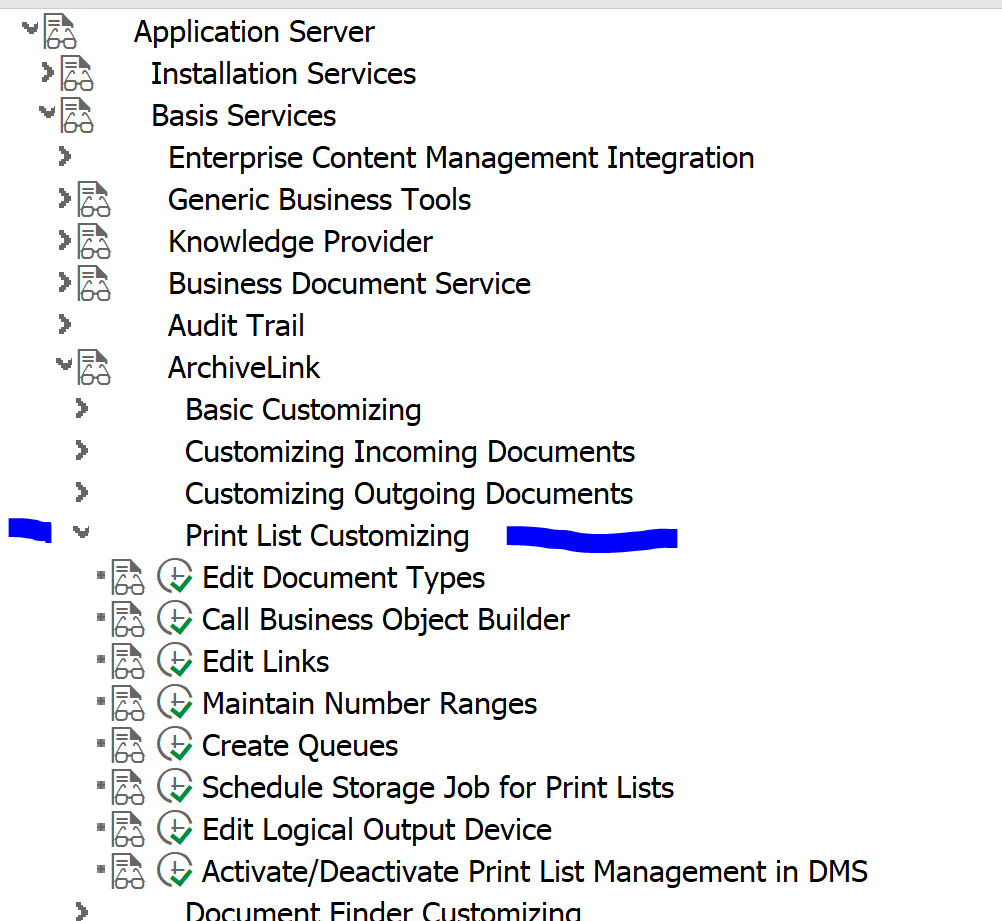
Customizing for print list archiving
In the following customizing path you find all the actions required for the print list archiving:
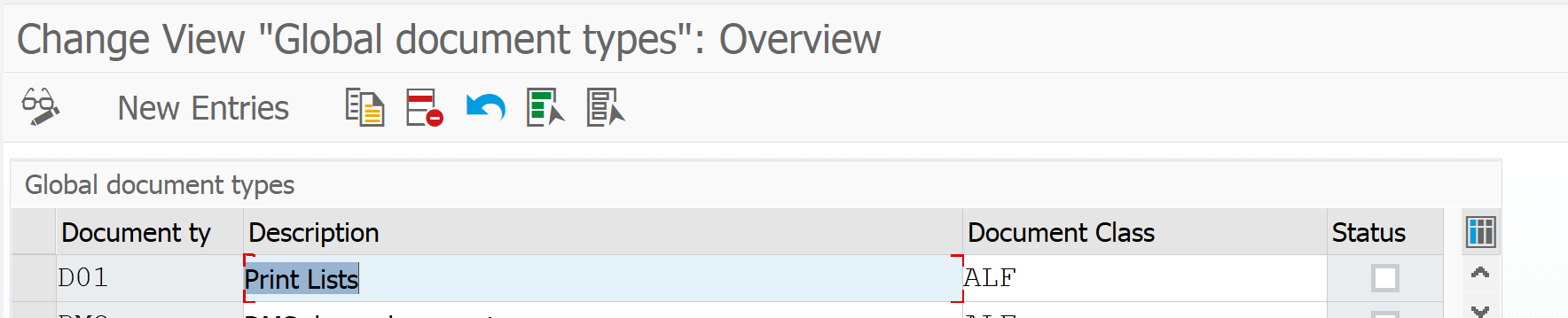
First check that print list document type D01 is present and is using ALF as document class:
In the Edit links section, you can set for document type D01 which content repository is should use.
Then check if the number ranges for archivelink are properly maintained (if empty create new number range):
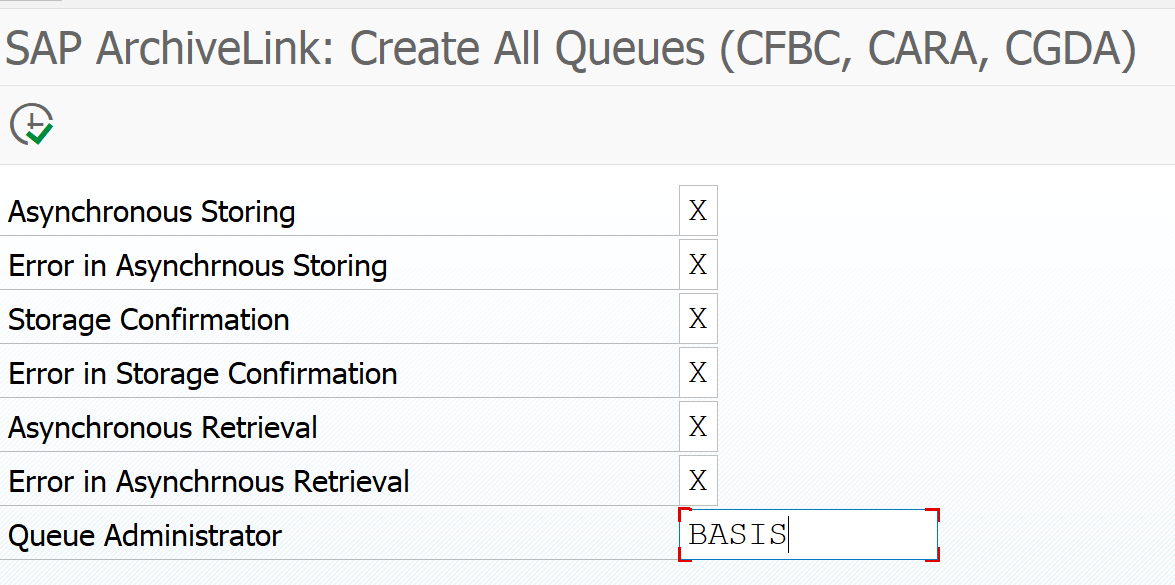
Then activate the print list queues:
Next step is to select the action to schedule the storage job. This job should not run faster than every 15 minutes.
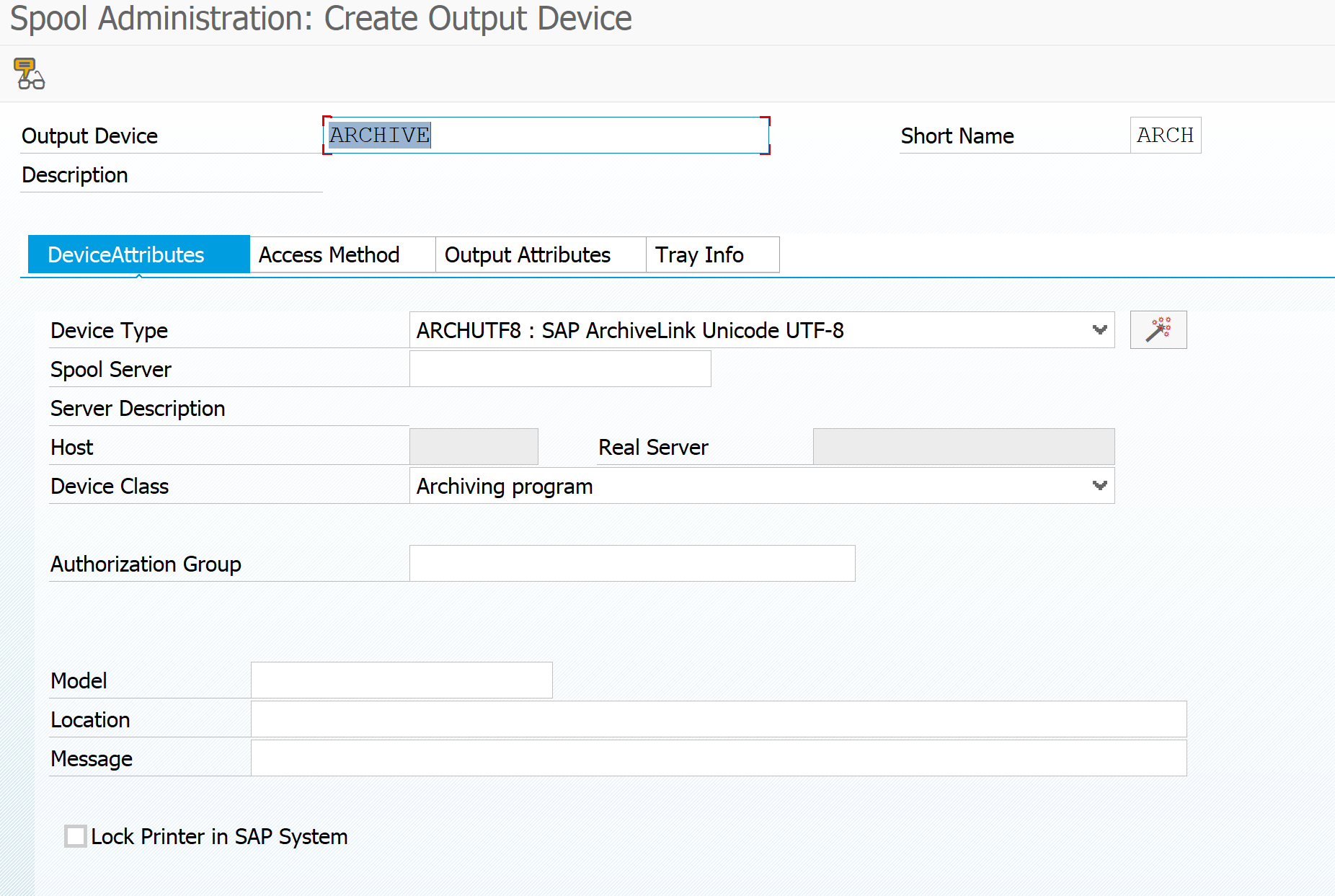
Final step is to setup the archive printer. You can later on see it with transaction SPAD as well.
Important here: short name must be ARCH. Device type and device class must be set to archiving.
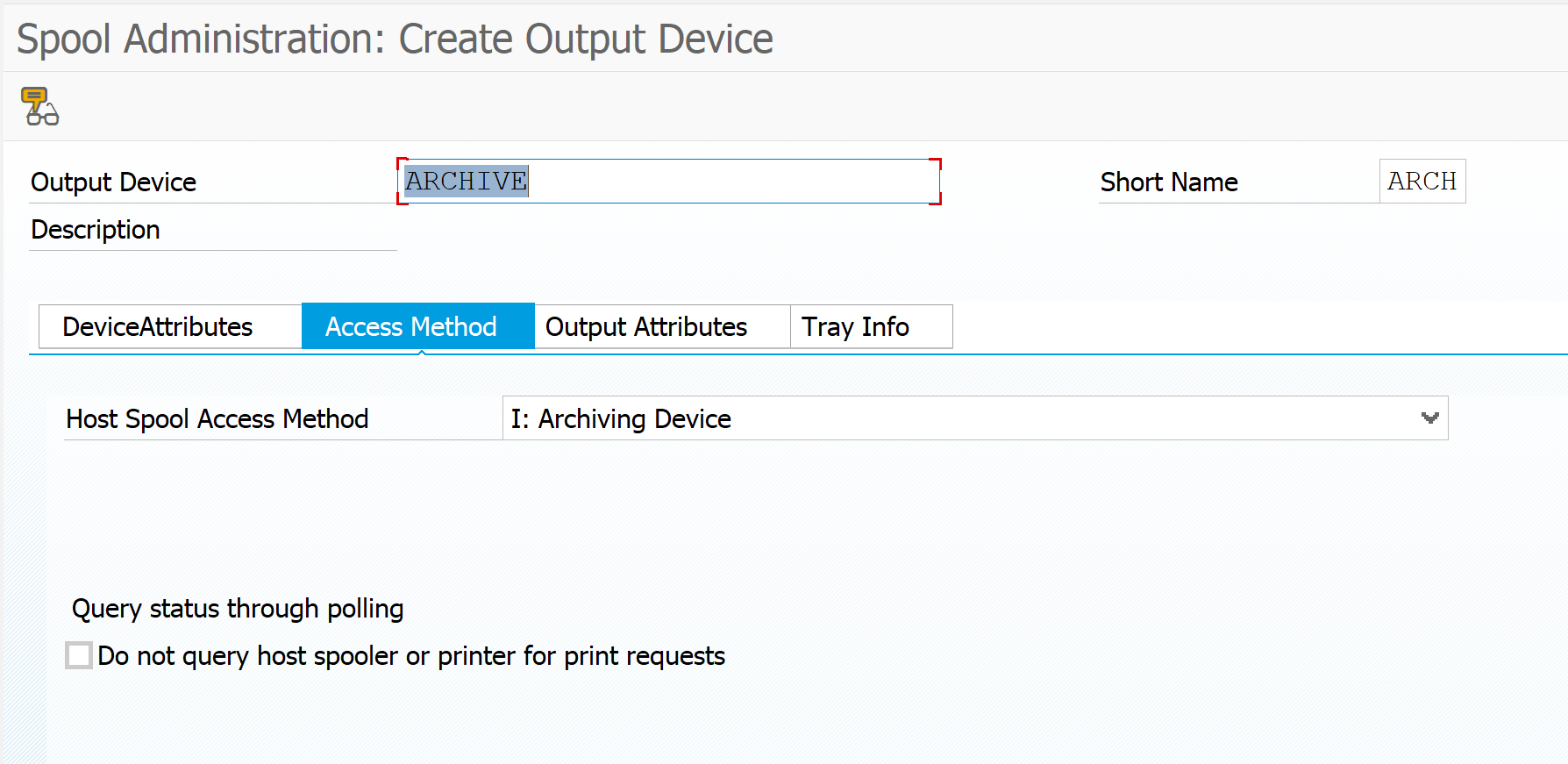
On the access method tab also set access method to archiving.
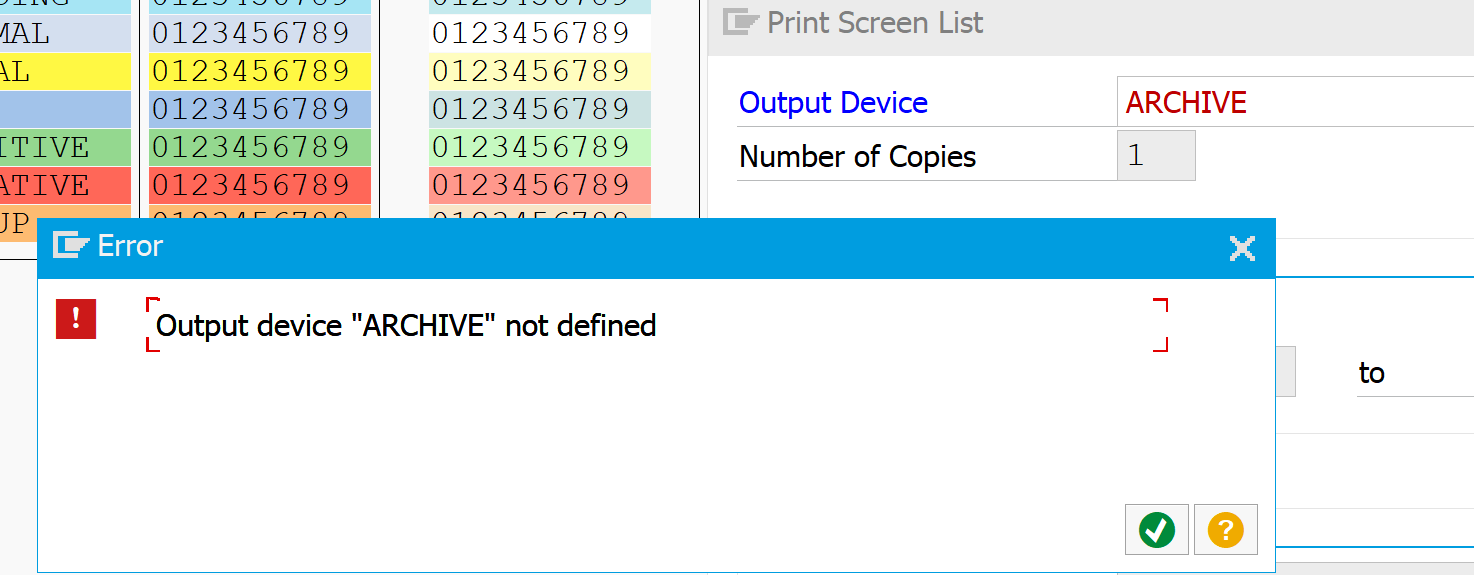
If you follow this procedure you will initially run into this strange screen:
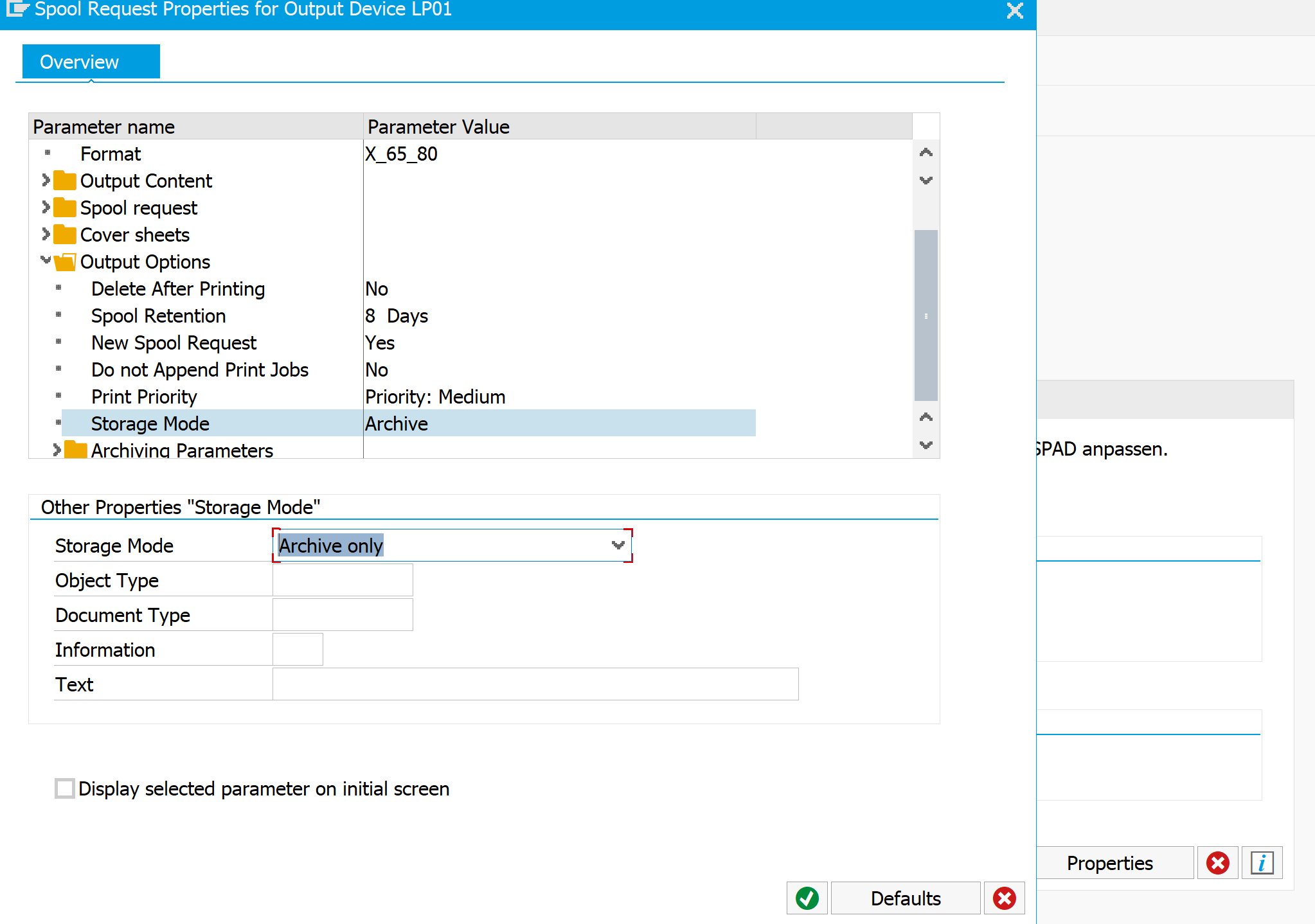
You didn’t do anything wrong yet. The problem is that the option for print to archive is not displayed by default. First go to the properties of a working printer to enable the archiving output option:
The rest of the note is self explaining:
Start SE38 and run program SHOWCOLO
Print the output list to printer ARCHIVE and archive mode selected
Goto SP01 find the spool, select menu path Print with changed parameters
Hit the Archive button
Start transaction OAM1 and hit the execute button next to Archive queue
Start transaction OADR to read from the archived print lists
From the list take the document and select the button “Display from storage system”