This blog will explain how to archive customer and vendor master data via objects FI_ACCRECV and FI_ACCPAYB. Generic technical setup must have been executed already, and is explained in this blog.
Most use of this archiving is when customers and vendors are created wrongly, to get them deleted from the system.
The below is mainly focusing on traditional ECC system. In S4HANA system both customers and vendors are integrated as business partners. For archiving sections of business partners for customer and / or vendors, read OSS note 3321585 – Archiving for Business Partner and Customer / Suppliers.
If you also want to archive/delete the LFC1 and KNC1 tables, also implement the FI_TF_DEB and FI_TF_CRE archiving objects.
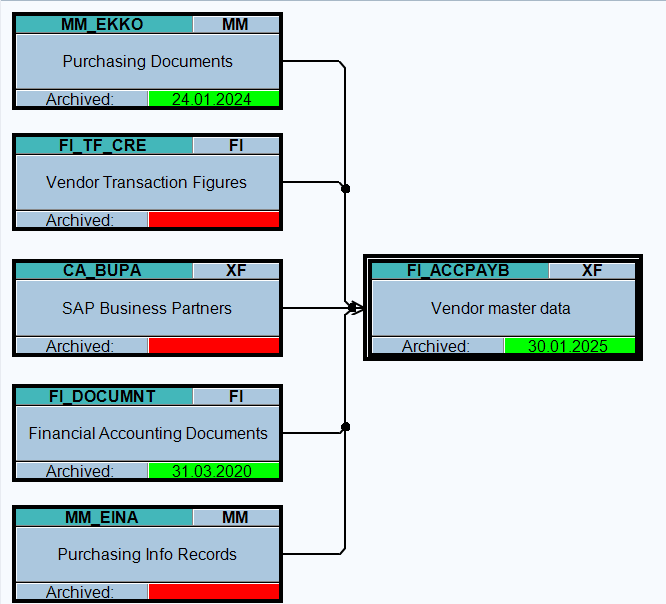
Object FI_ACCRECV (customers)
Go to transaction SARA and select object FI_ACCRECV (customers).
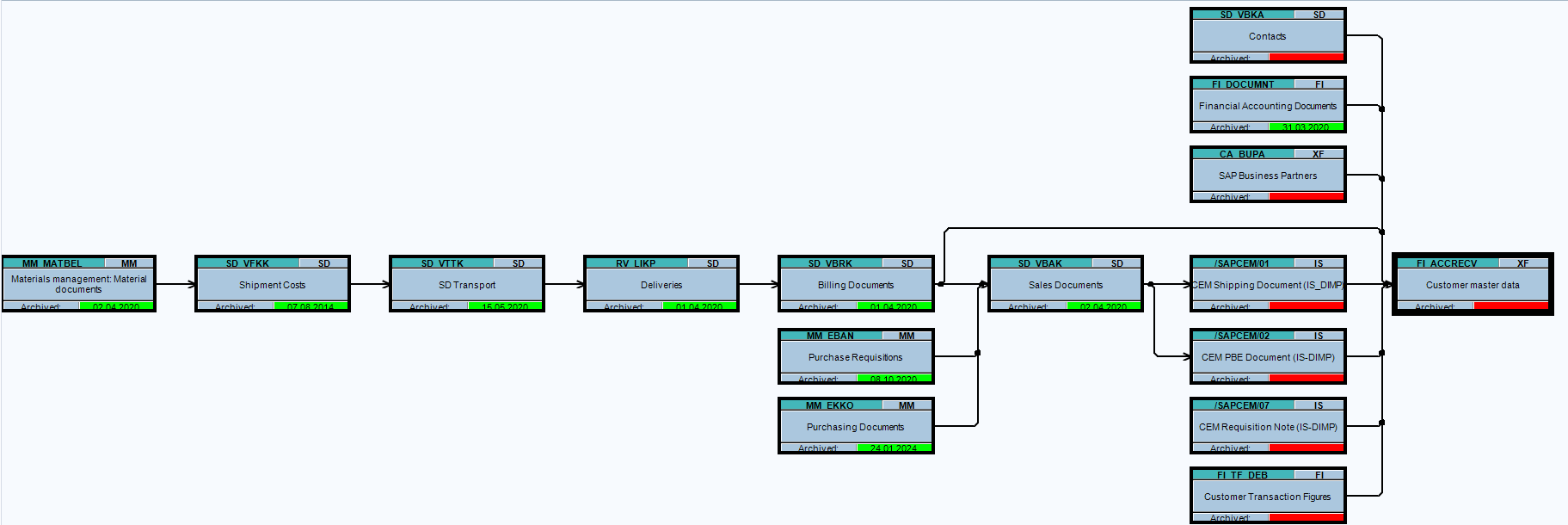
Dependency schedule:
A lot of dependencies. Everywhere a customer number is used in an object. This makes it almost impossible to archive a customer master record. But still: it can be done to delete wrongly created master data if no transaction data is created yet.
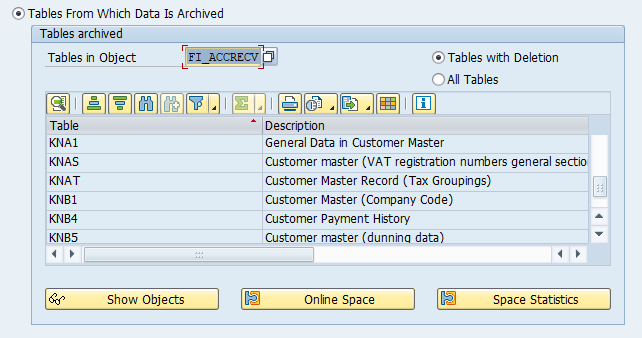
Main tables that are archived:
KNA1: General customer master data
KNB1: Company code specific customer master data
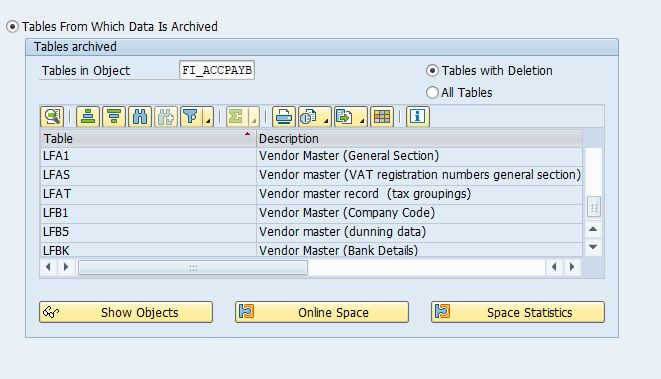
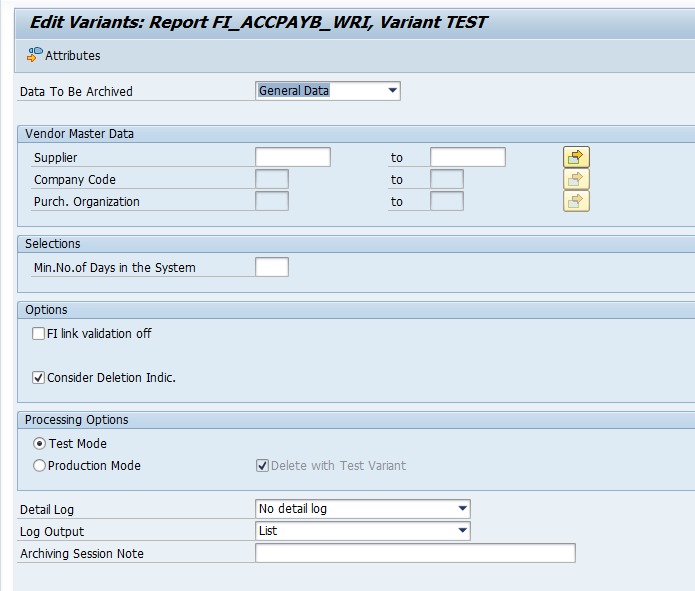
Object FI_ACCPAYB (vendors)
Go to transaction SARA and select object FI_ACCPAYB (vendors).
Dependency schedule:
Quite some dependencies. Everywhere a customer number is used in an object. This makes it almost impossible to archive a vendor master record. But still: it can be done to delete wrongly created master data if no transaction data is created yet.
There is no application specific customizing for customer and vendor archiving. You can use XD06 for customer master deletion flag setting and XK06 for vendor master deletion flag setting.
Executing the write run and delete run Customers
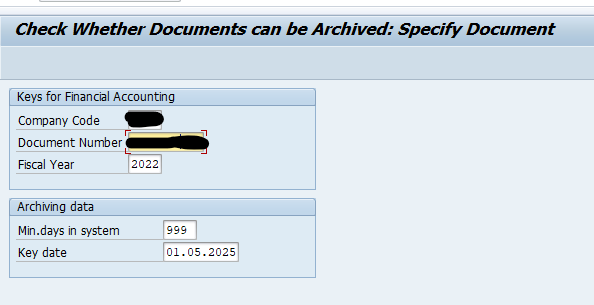
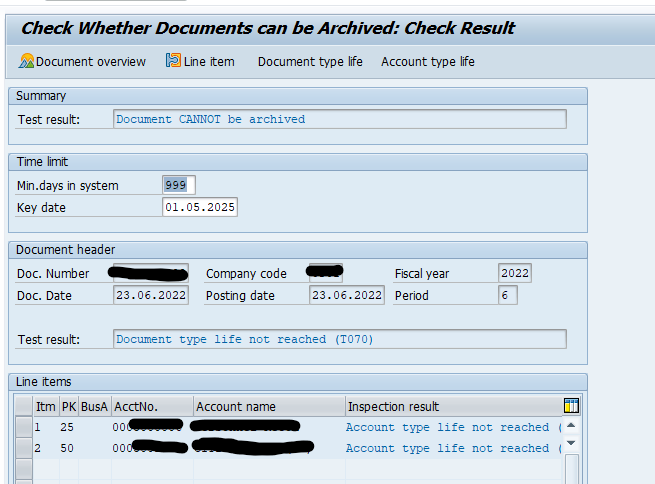
For customers: in transaction FI_ACCRECV select the write run:
Important is the consideration of the validation links and the deletion indicator. Customer deletion indicator flag can be set with transaction XD06.
Select your data, save the variant and start the archiving write run.
SAP BI can be used in BI itself, but BI is more available than you think: embedded BI in S4HANA, inside SCM, inside SAP solution manager, etc.
Also for BI systems a technical clean up of data might be required when the data volume becomes too high. For other clean up read this blog on technical clean up.
Questions that will be answered in this blog are:
How can I do a housekeeping on my BI system using a task list?
How can I execute a technical clean up of old BI technical data?
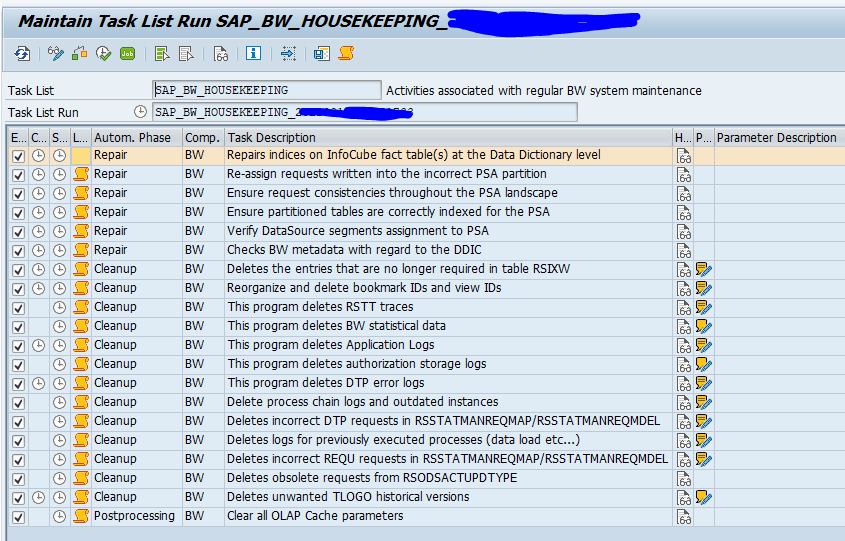
BI housekeeping task list
Go to transaction STC01 and start the SAP_BW_HOUSEKEEPING task list. Select all cleanups you want to perform. Select in the variants the retention times and dates. When done, start the task list (best to do in background mode):
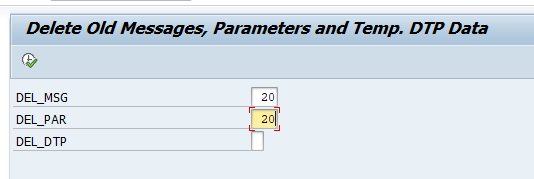
For Clean up of tables RSBATCHDATA and RSBATCHCTRL, you can use program RSBATCH_DEL_MSG_PARM_DTPTEMP (transaction RSBATCH):
Parameters: DEL_MSG to delete all records older than XXX (From 000 to 999) days (M-Records). DEL_PAR to delete all records older than XXX (From 000 to 999) days (R and P-Records). DEL_DTP has no meaning.
With data archiving you reduce the database size of SAP and increase the performance by reducing the amount of records in the SAP tables. The data archiving process write files with the archived data. These files must still be stored securely, since on file level any admin can delete the files and you might loose valuable business data.
This blog explains the setup of storage of data archiving files by using SAP content server as storage medium.
Questions that will be answered are:
How do I setup the link from SAP netweaver ABAP stack to the SAP content server?
Which settings do I need to make in the archiving objects to store the archiving file to SAP content server?
How do I store the files in the SARA transaction?
General tips and tricks for SAP content server can be found in this blog.
Setup of SAP content server 7.5 information can be found in this blog.
How to setup archiving technically can be found in this blog.
Linking the SAP Netweaver ABAP stack to SAP content server
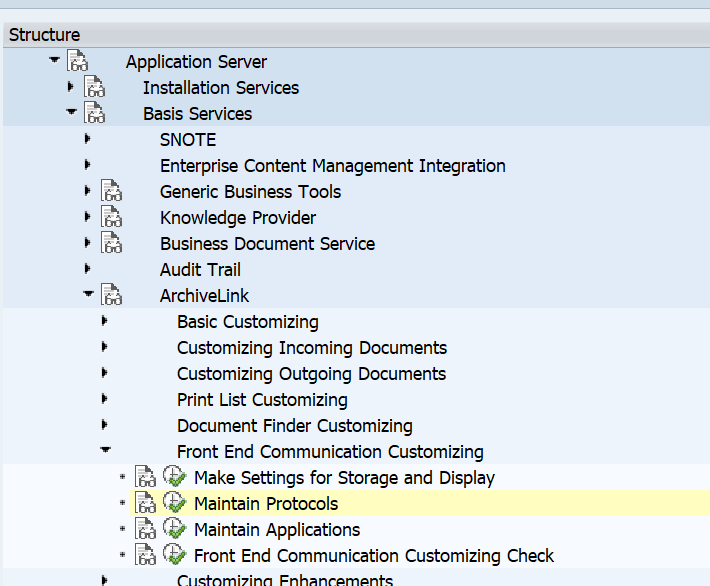
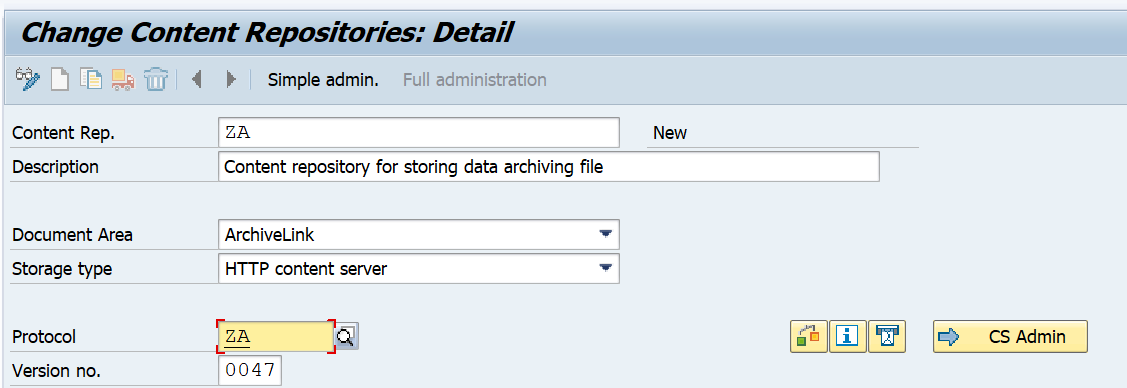
First we need to maintain a special protocol in customizing using this path:
Create a new protocol:
This protocol can now be assigned to the SAP content server you want to use for storing the data archiving files. Go to transaction OAC0 to link the protocol to your content server:
If the field protocol is not visible immediately there, click the button Full administration first.
Data archiving object specific linking
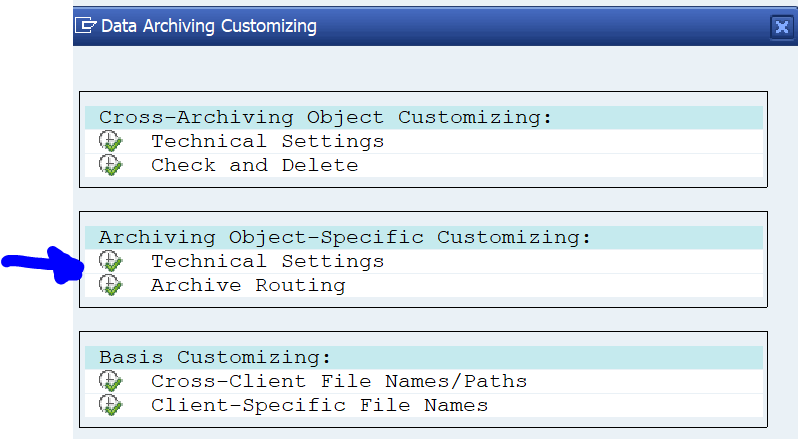
After the steps above to make the general connection to content server available, the content server needs to be explicitly mentioned in each data archiving object. For any data archiving object (start transaction SARA first and select the object), click on the customizing button:
In the popup screen now select Technical Settings in Archiving Object-Specific Customizing:
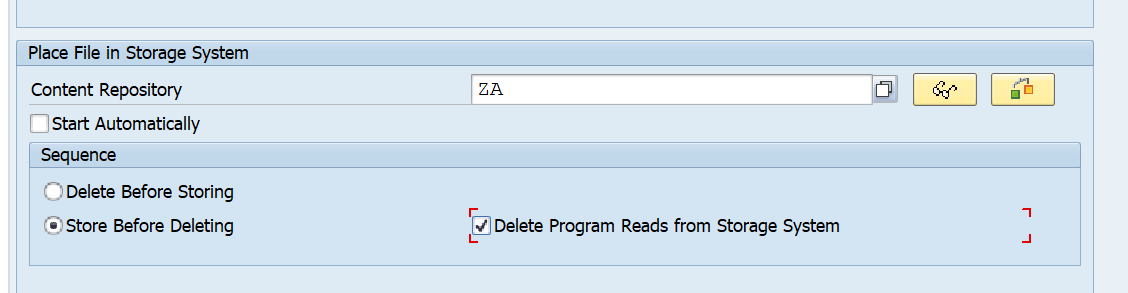
At the bottom fill out the content server repository and decide if you want to start automatically or immediately:
Remark 1: the F4 search help does not work here! Key in the value directly and check using the check button. Then save the data.
Remark 2: always tick the option Delete Program Reads from Storage System. This forces that the archive file is securely stored first, before the deletion run is allowed to start.
Use of archive routing
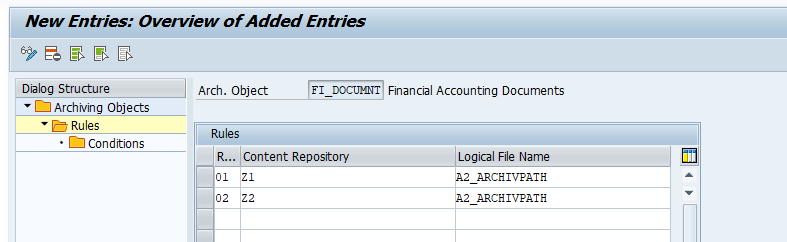
If you have a lot of archiving data and a lot of years of archiving done, it can be needed to set up a second or third content server.
With the use of Archive Routing you can determine in which content server to store which archive files.
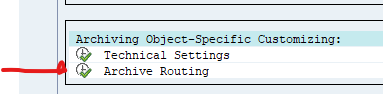
On the SARA screen push the customizing button and select Archive Routing:
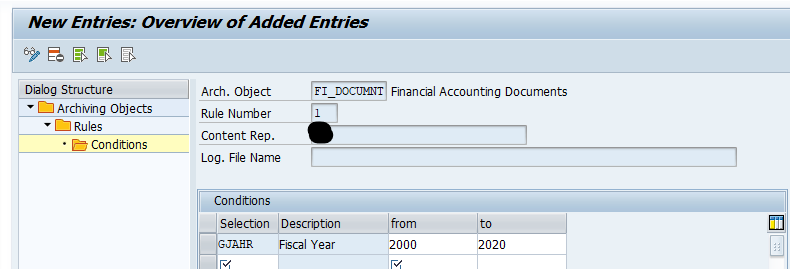
Now set up a rule:
And the conditions of the rule:
This setting does NOT work for the CHANGEDOCU object. To achieve the same for CHANGEDOCU, you must switch to the licensed SAP ILM product.
Storing archive files in SARA
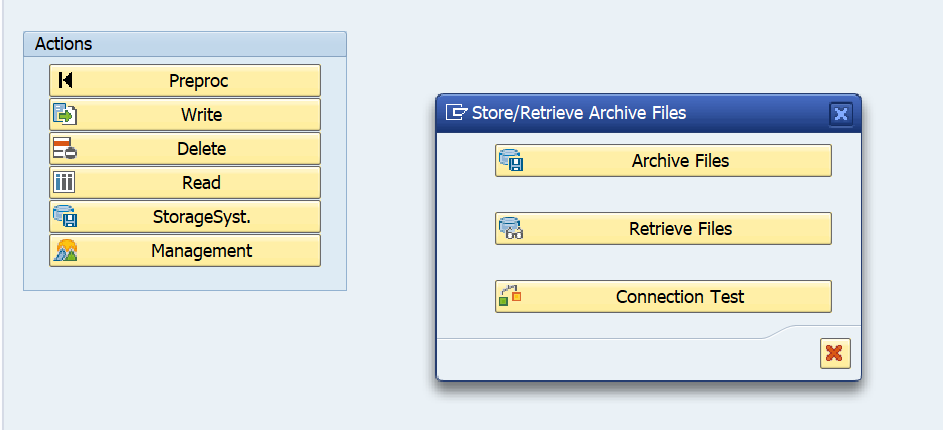
After the configuration is done the new button Storage system appears on the screen in the SARA transaction for this specific object:
If the button does not appear: check the technical settings above, and remember: this is to be repeated for each object.
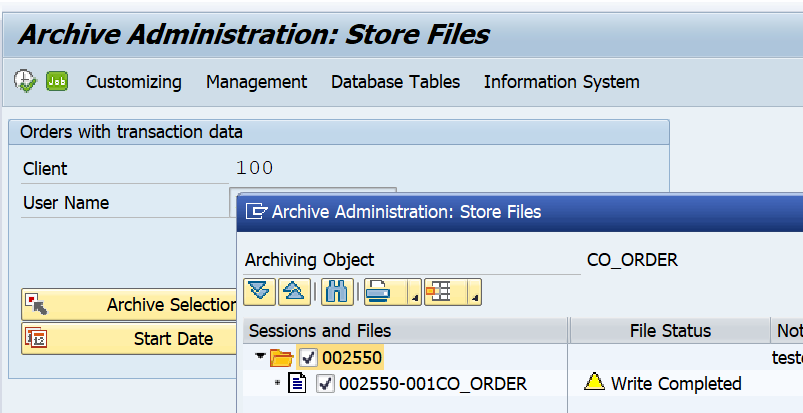
Storing files that have been written by the Write phase of the data archiving process can now be stored by pressing the Archive Files button:
Select the file(s) to store:
Now a batch job starts (per file!) to store the archive file into the SAP content server.
After correct storage of the file, the file can be selected in the delete phase.
This blog will explain how to setup print list archiving.
Questions that will be answered are:
What is use case of print list archiving?
How to setup print list archiving?
How to test print list archiving?
How to troubleshoot issues with print list archiving?
Goal of print list archiving
The business sometimes needs to store report output for a longer period of time. They can print the information and put it in their archive. This leads to a big physical archive.
You can also give the business the option store their output electronically in the SAP content server.
Set up or check content repository
First check which content repository you want to use to store the print lists. The type of content repository must be “ARCHLINK”. Menu path in customizing is as follows:
Or you can go there directly with transaction OAC0.
Content repository A2 is default present in the system and is used in the example below. A2 is pointing towards the SAP database for storage. For productive use a SAP content server in stead of SAP database.
Customizing for print list archiving
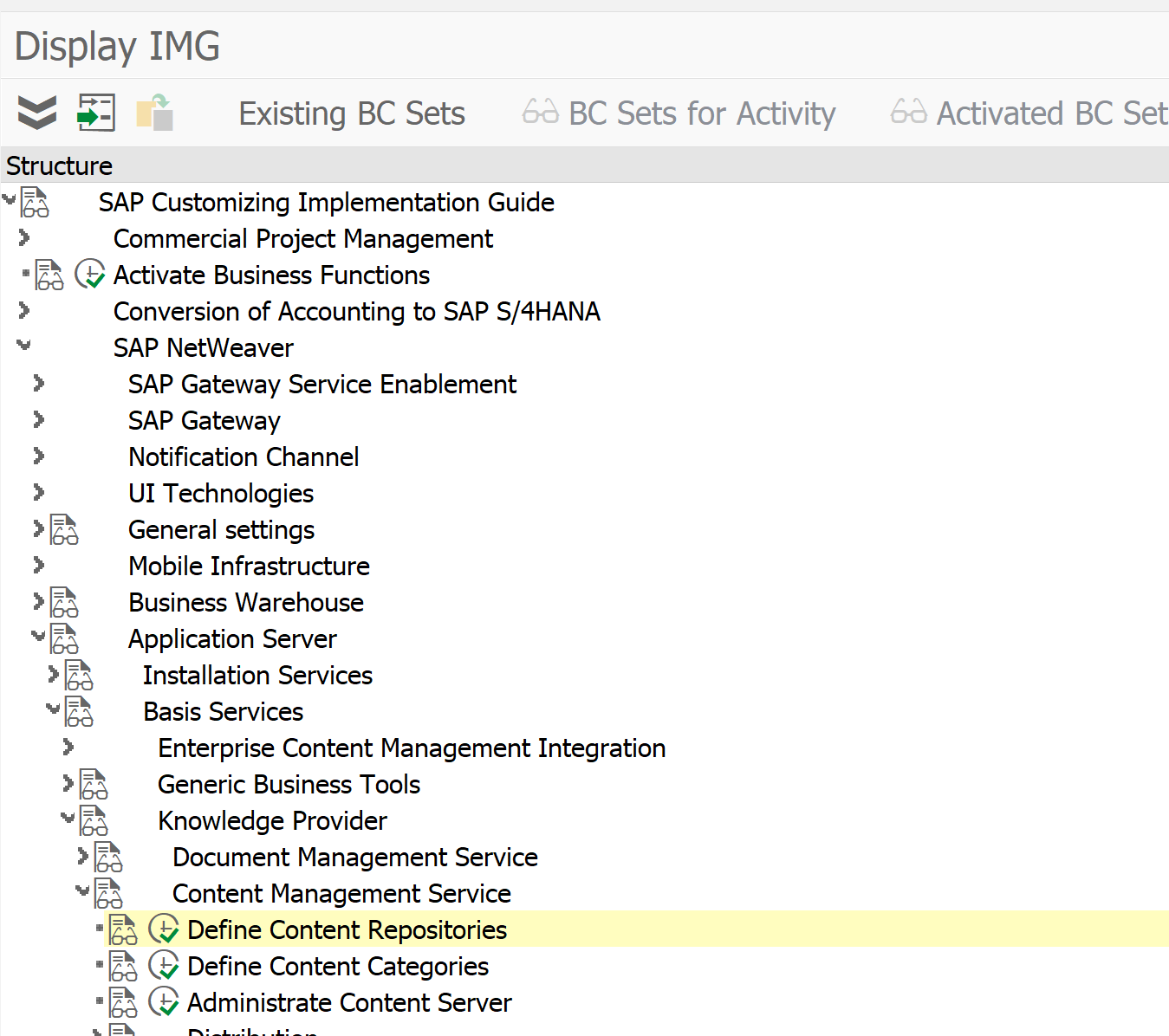
In the following customizing path you find all the actions required for the print list archiving:
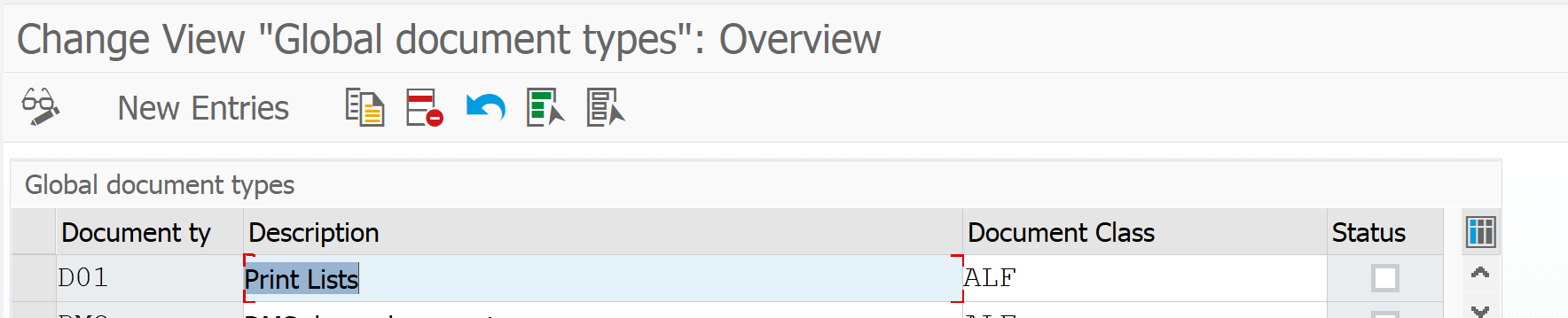
First check that print list document type D01 is present and is using ALF as document class:
In the Edit links section, you can set for document type D01 which content repository is should use.
Then check if the number ranges for archivelink are properly maintained (if empty create new number range):
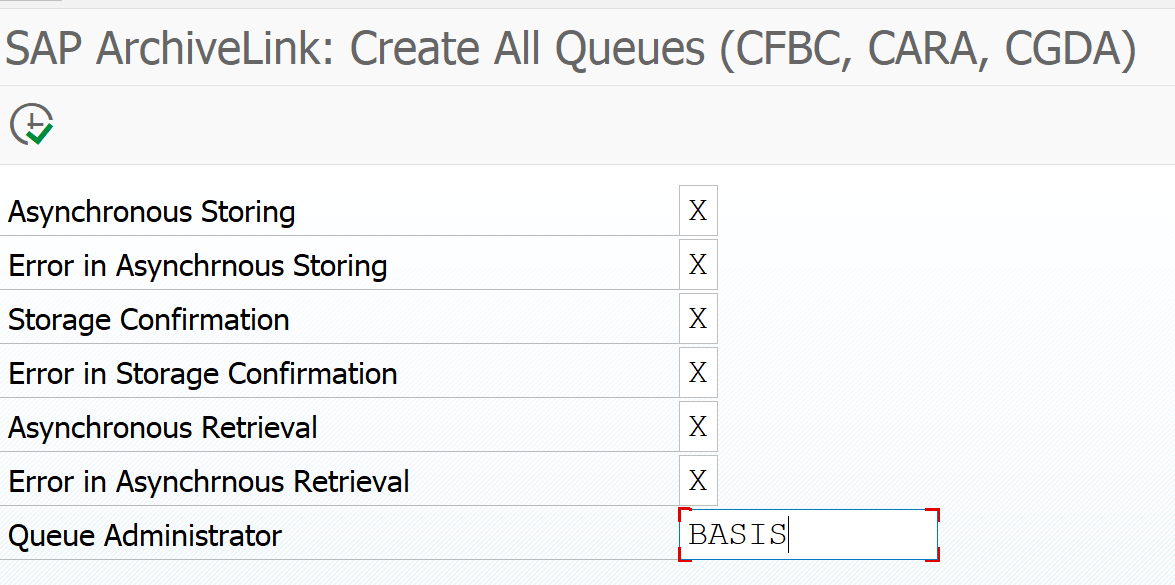
Then activate the print list queues:
Next step is to select the action to schedule the storage job. This job should not run faster than every 15 minutes.
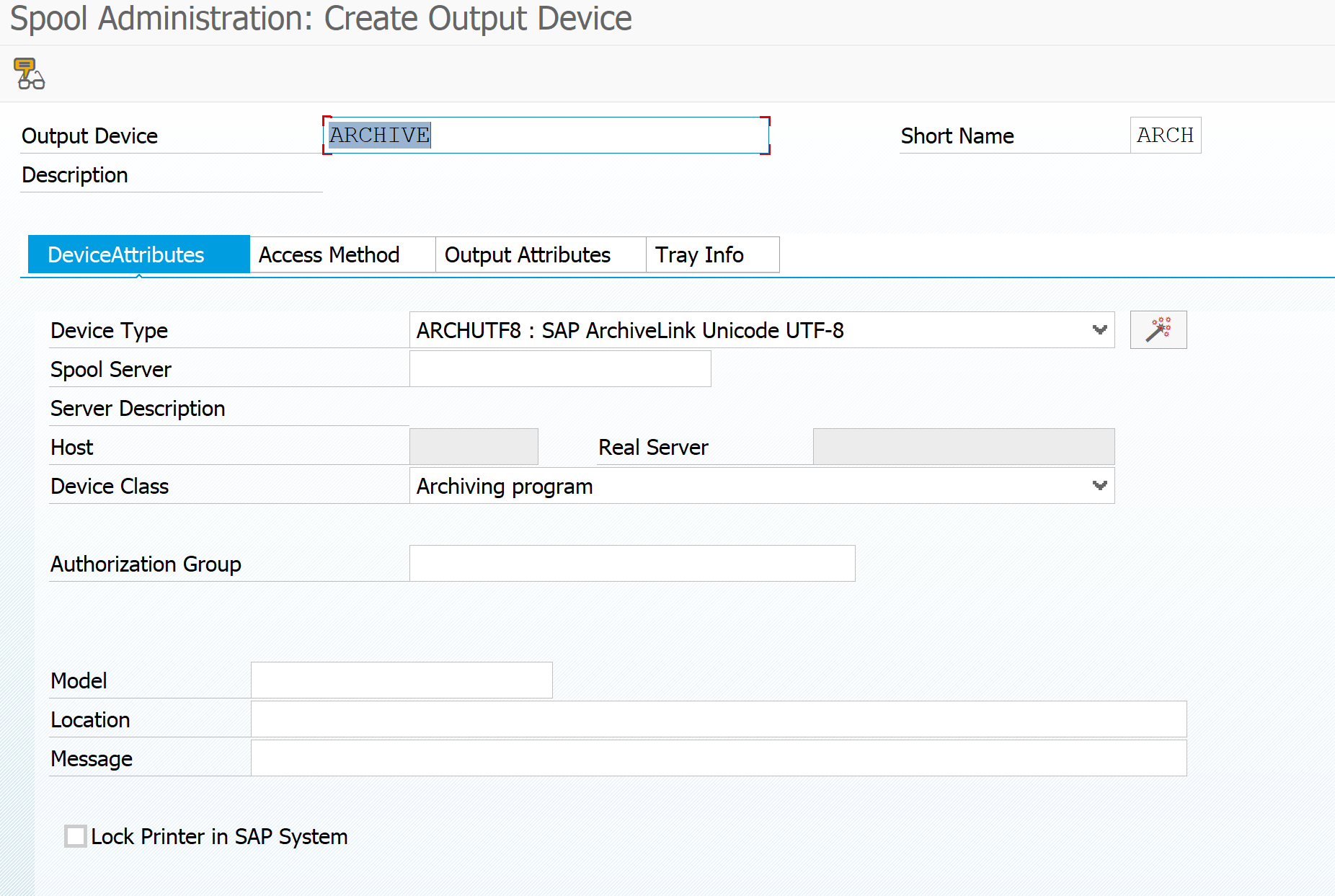
Final step is to setup the archive printer. You can later on see it with transaction SPAD as well.
Important here: short name must be ARCH. Device type and device class must be set to archiving.
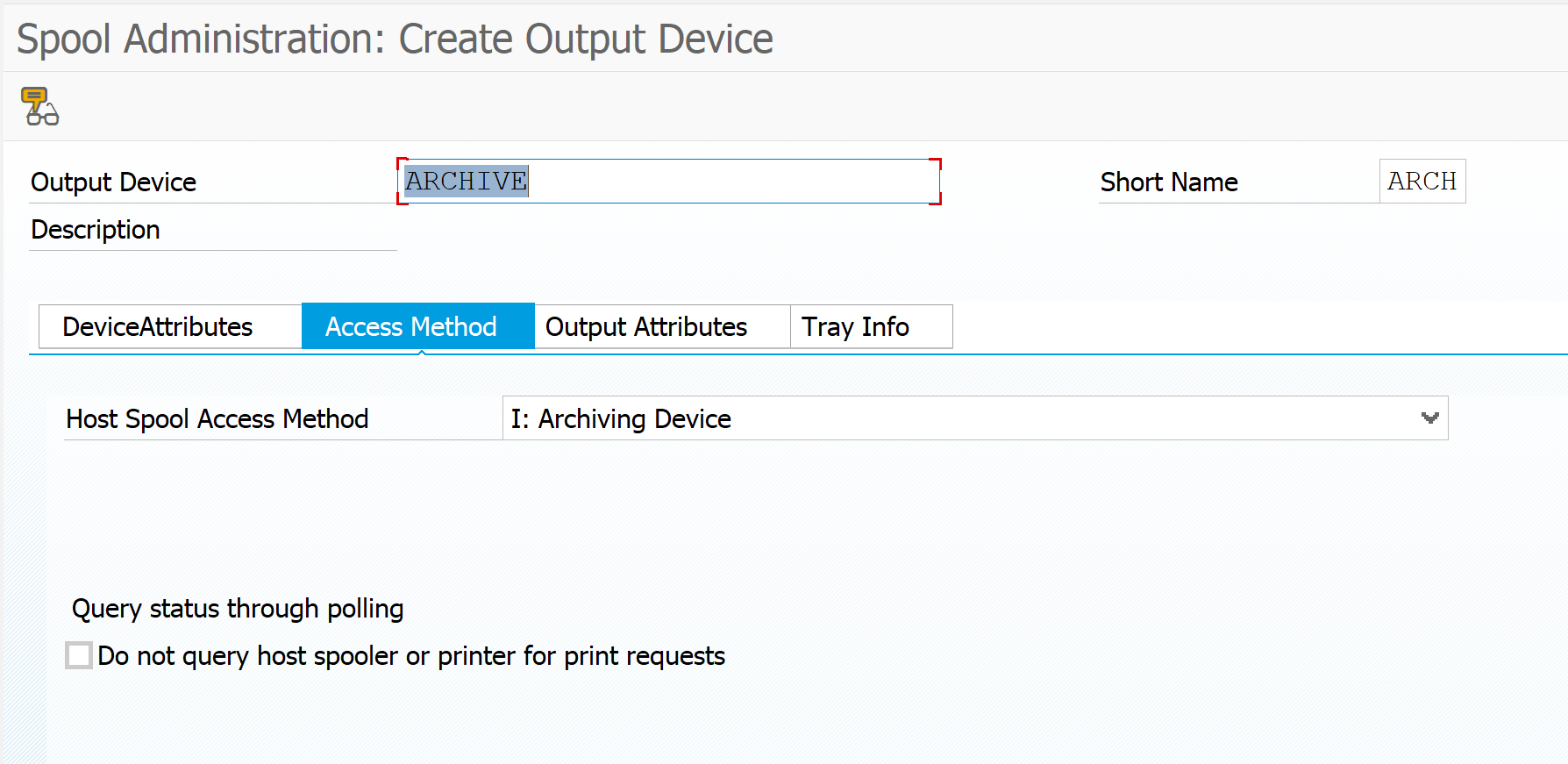
On the access method tab also set access method to archiving.
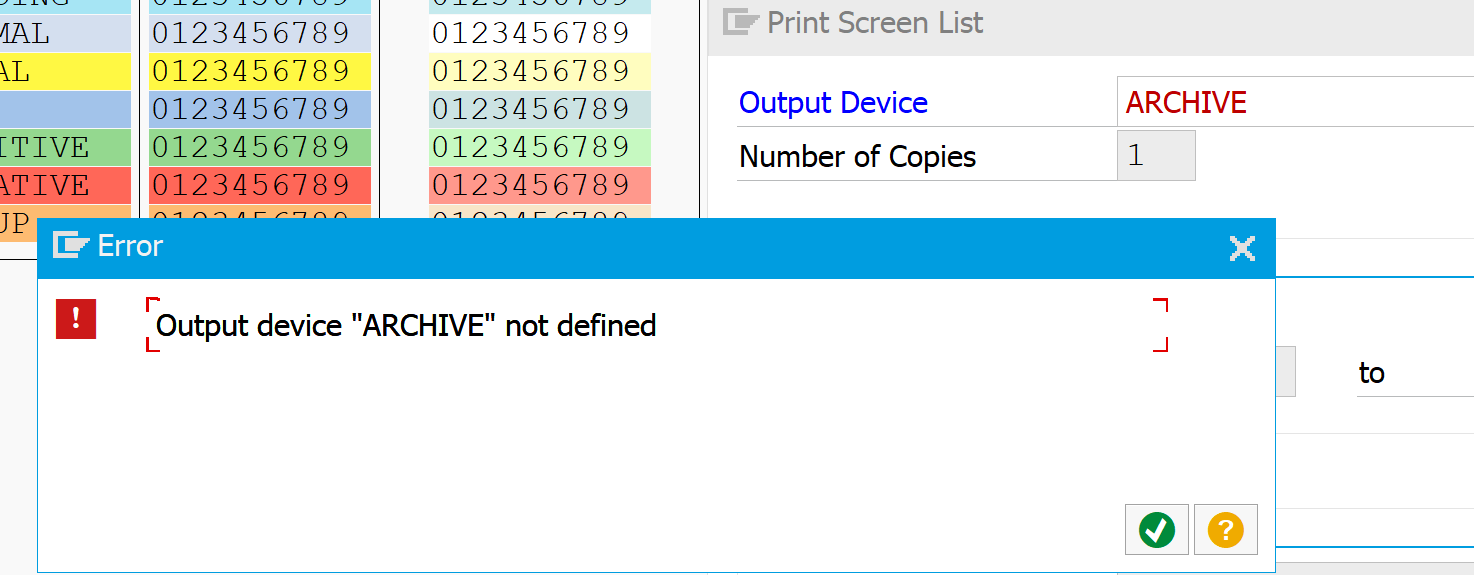
If you follow this procedure you will initially run into this strange screen:
You didn’t do anything wrong yet. The problem is that the option for print to archive is not displayed by default. First go to the properties of a working printer to enable the archiving output option:
The rest of the note is self explaining:
Start SE38 and run program SHOWCOLO
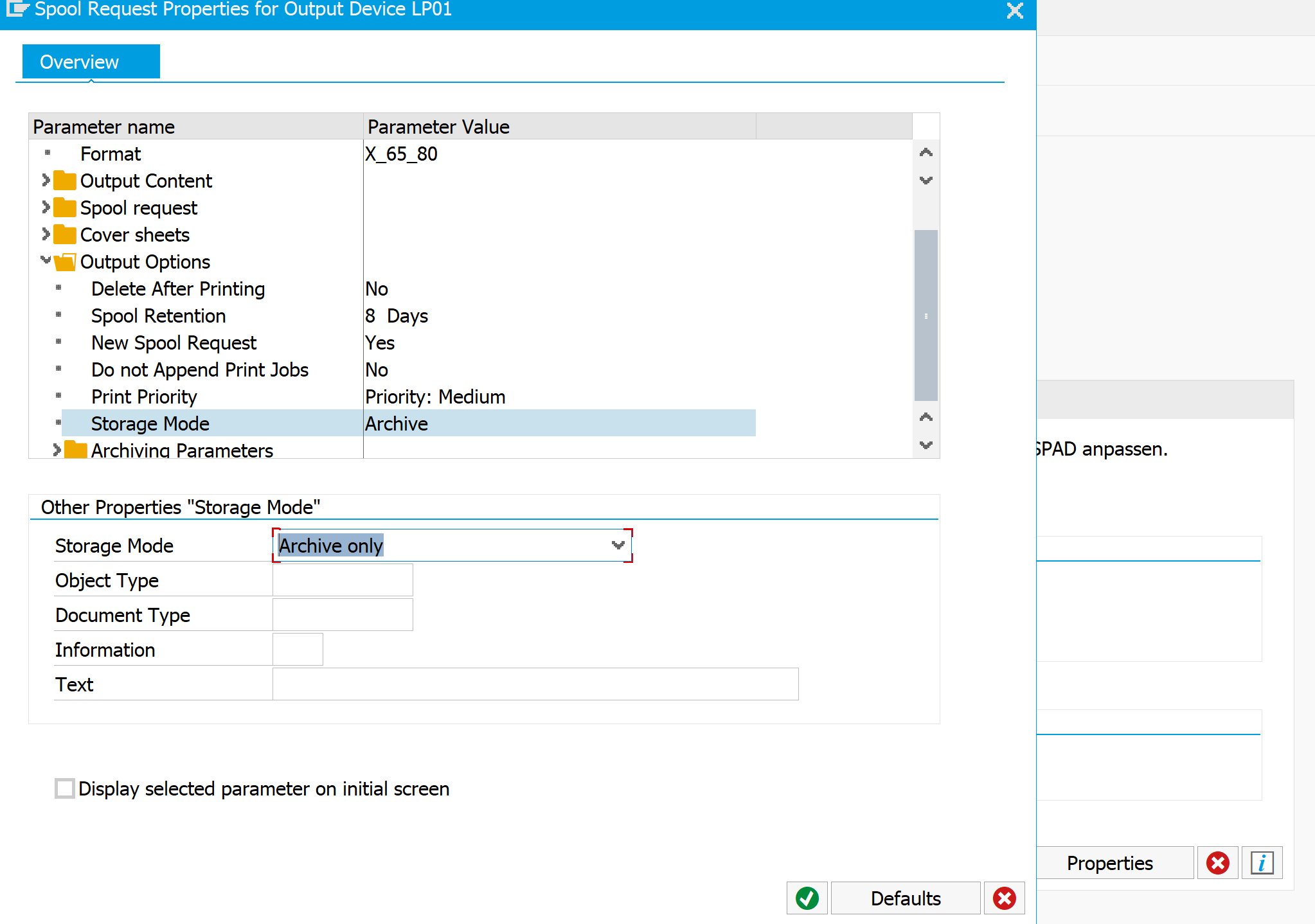
Print the output list to printer ARCHIVE and archive mode selected
Goto SP01 find the spool, select menu path Print with changed parameters
Hit the Archive button
Start transaction OAM1 and hit the execute button next to Archive queue
Start transaction OADR to read from the archived print lists
From the list take the document and select the button “Display from storage system”
HANA data aging is a method to reduce the memory footprint of the HANA in-memory part without disturbing the end users. It is not reducing your database size.
How to set up HANA data aging for technical objects?
What about data aging for functional objects?
What is HANA data aging?
HANA data aging is an application method to reduce the memory footprint based on application data logic. It is not a database feature but an application feature. The goal of HANA data aging is not to reduce the database size (which it is not doing), but to reduce the actual memory footprint of the HANA in-memory database.
Let’s take idocs as example: the idocs that are processed ok you need to keep in database for an agreed amount of time before business or audit allows you to delete them. Lets say you can only delete after 1 year. Every action on idocs now means that full year of idoc content is occupying main memory. For daily operational tasks you normally only need 2 months of data in memory and rest you can accept that it will take bit longer to read from disc into memory.
This is exactly what data aging is doing: you partition the data into application logic based chunks. In this case you can partition the idoc data per month and only have last 2 months in active memory. The other 10 months are on disc only. Reading data of last 2 months is still fast as usual. When having to report on the 10 months on disc, the system first needs to load from disc into memory; will be slower.
To reduce database itself, you would still need to do data archiving.
Advantage of the data aging is that the more expensive memory footprint costs can be reduced in such a way that the end users are not hampered. Data aging is transparent for them. With data archiving the users will always need to select different transaction and data files.
How to switch on data aging?
To switch on data aging on system level you need to do 2 things:
Set the parameter abap/data_aging to on in RZ11
In SFW5 switch on the switch called DAAG_DATA_AGING
This only enables the system for data aging.
Data aging switch on for technical object: example for application logging
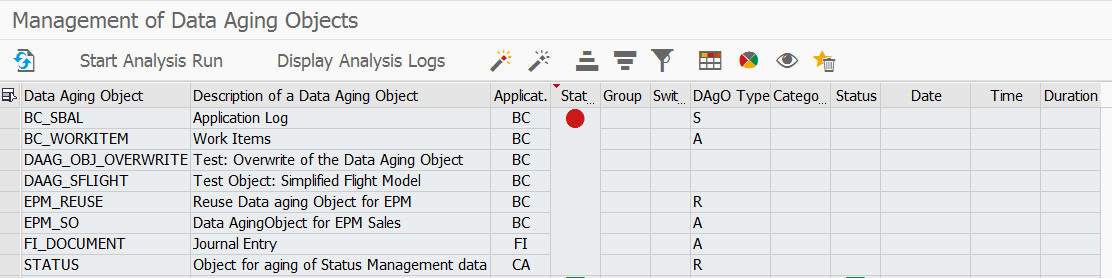
With transaction DAGADM you can see the administration status of the data aging object. You first see red lights that the objects are not activated for data aging.
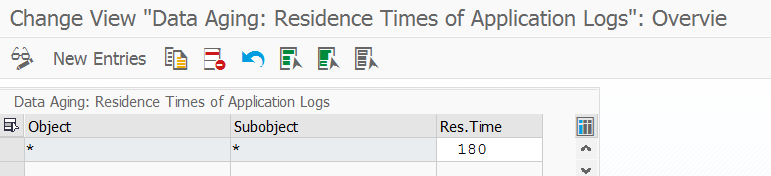
Per object you have extra transactions (which unfortunately differ per object…) to set the retention times. For application logging this is transaction SLGR. Here we choose in this example to data age all log after 180 days:
The advantage of this tailoring is that you could only age some of the objects if you want.
The transaction and OSS note for each of the objects can be found on this SAP blog.
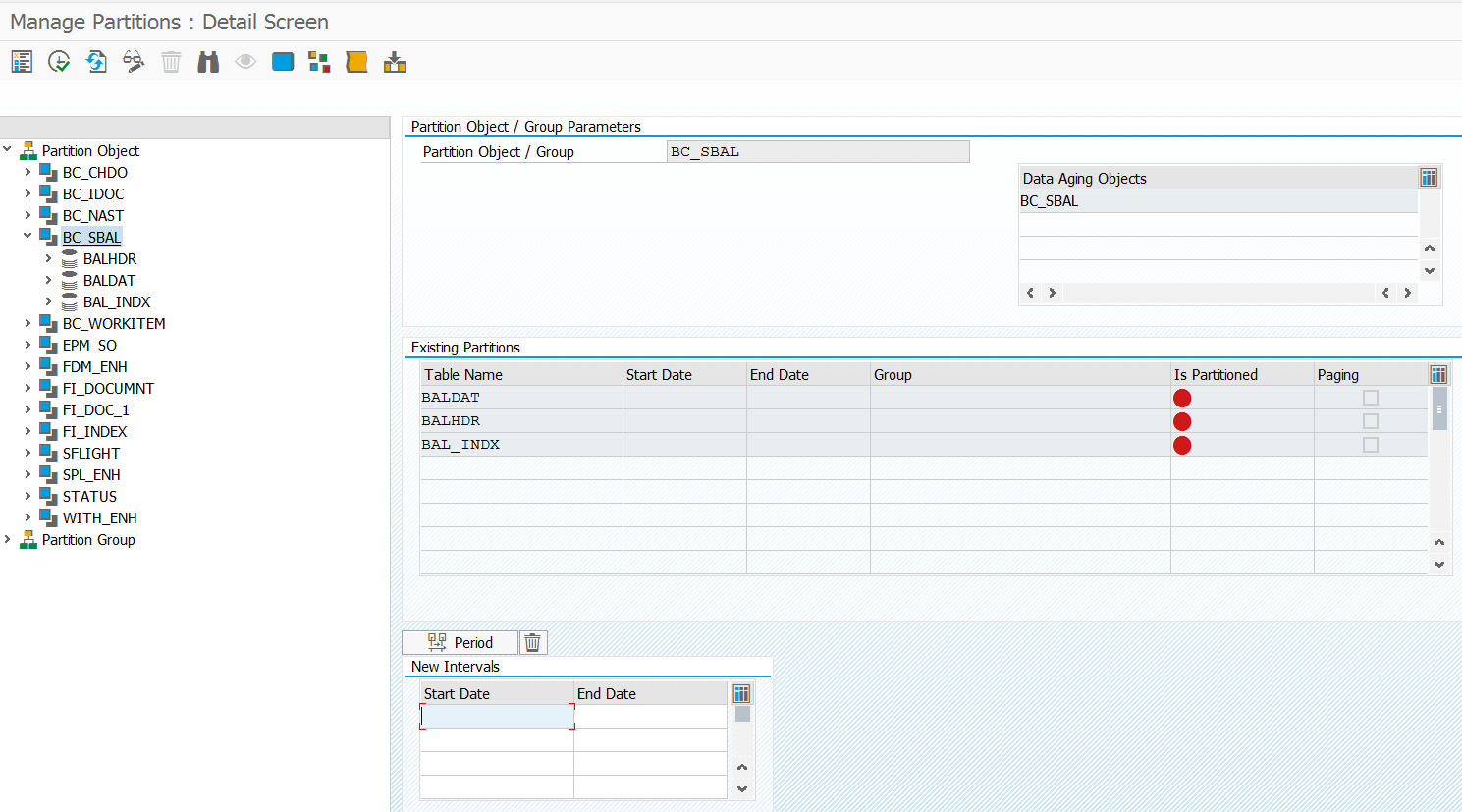
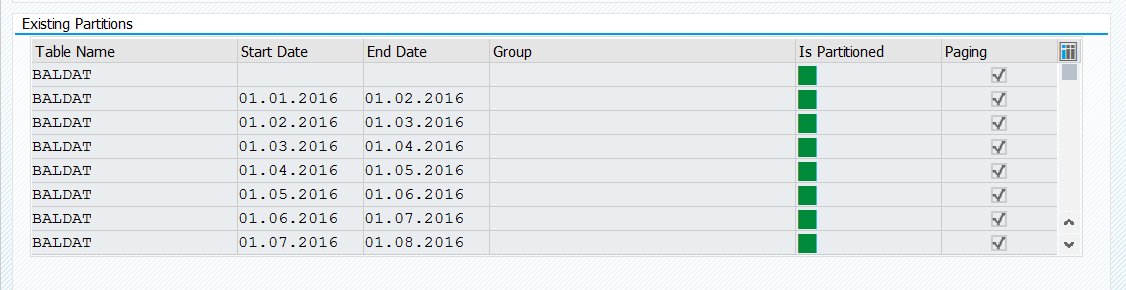
Next step is to setup partitions for the object. To do this start transaction DAGPTM and open the object you want to partition:
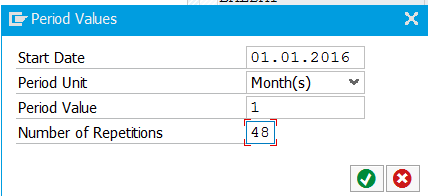
Initial screen is in display mode. Hit change button. On the bottom right side hit the Period button (Selection Time Period). In the popup enter the desired start date, time buckets (months, years) and amount of repetitions:
Now the partitions are defined. To execute the partitioning hit the execute button to start the partitioning in the background. Wait until the job finishes. Before running this on productive system check the runtime first on non-productive system with about same data size if possible.
After partitioning the screen should look like this:
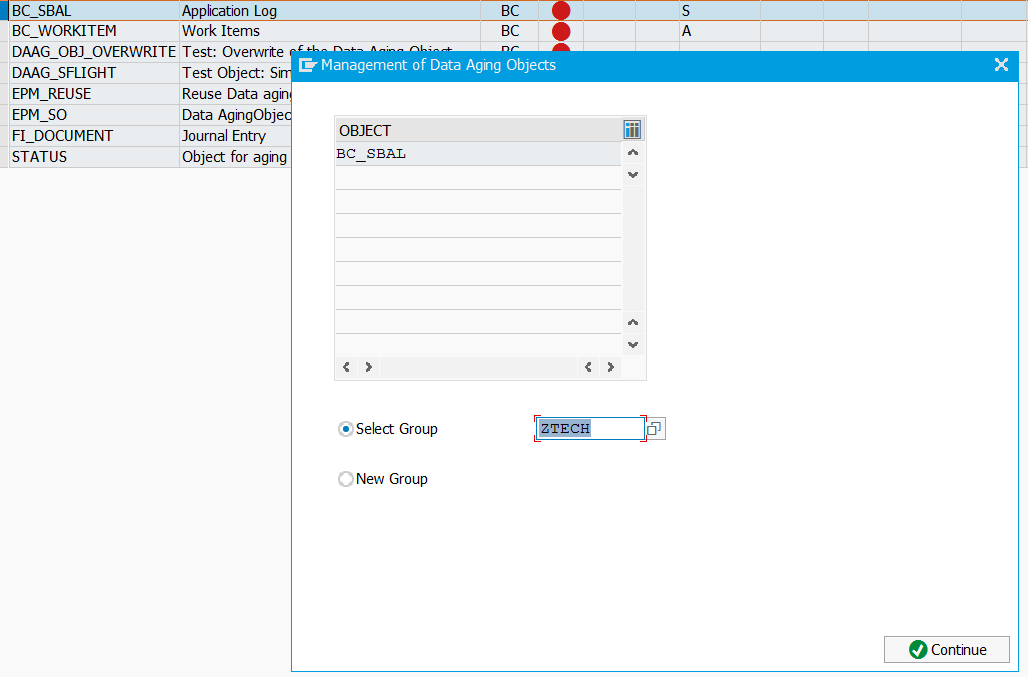
Now we can activate the object in transaction DAGADM. Select the object and press the activate button. Popup appears to assign the object to existing data aging or new group:
The data aging run will be done per group.
To start the actual data aging run start transaction DAGRUN.
Here you can schedule a new run with the Schedule new run button.
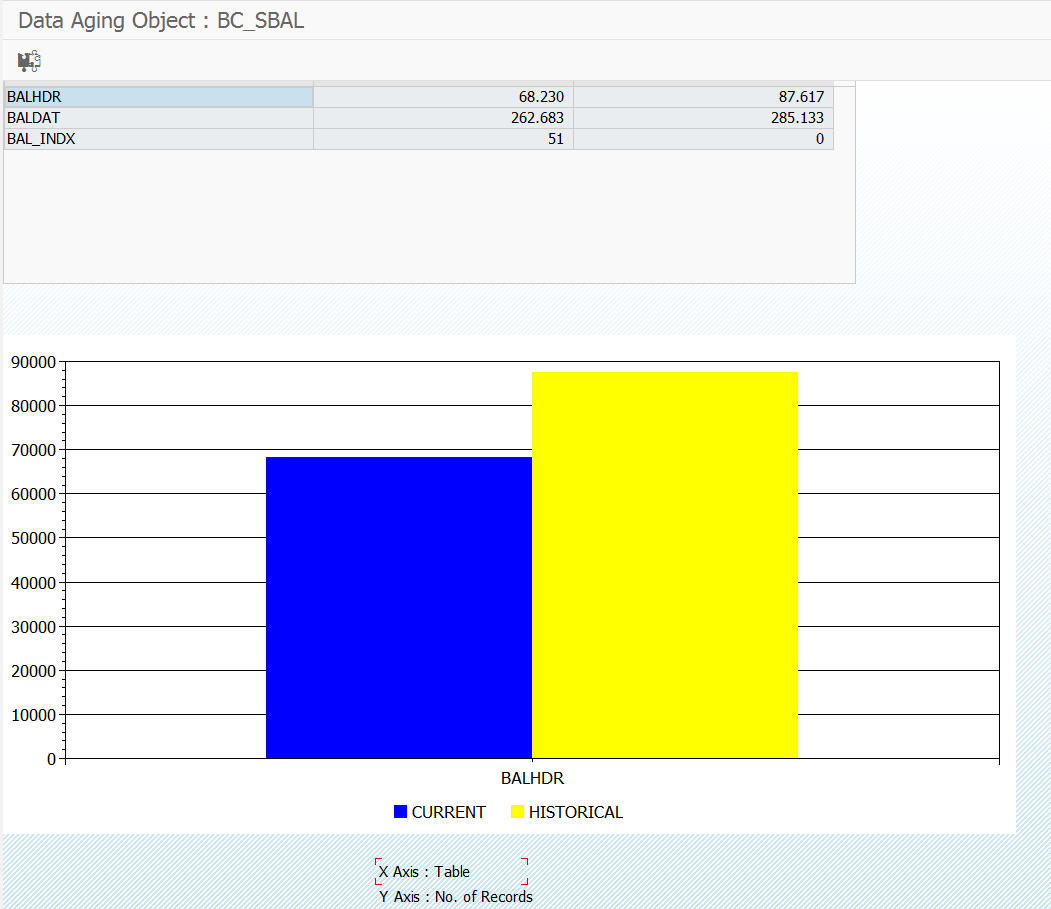
To see the achieved results of the data aging go to transaction DAGADM and select the object. Then push the button View current/Historical data.
Functional data aging objects
Functional data archiving objects exist as well for Financial documents, sales orders, deliveries, etc. The full list and minimal application version can be found on this SAP blog.
Words of caution for functional archiving:
The technical archiving objects are more mature in coding and usage. They are used in productive system and are with lesser bugs than the technical objects
Before switching on a functional data aging object you need to prepare your custom ABAP code. If they are not adjusted properly to take the partitions with the date selections (or other application selection mechanism) into account all benefits are immediately lost. A Z program that reads constantly into full history will force a continuous read of historical partitions….
This blog will explain about technical cleanup to reduce the SAP database growth and to regain control of it.
Questions that will be answered are:
How to run the standard SAP clean up jobs?
Where can I find full list of items that could be cleaned up?
How to run the cleanup of some common objects?
Database reorganization after cleanup?
How can I clean up old idocs?
How can I clean up old table logging?
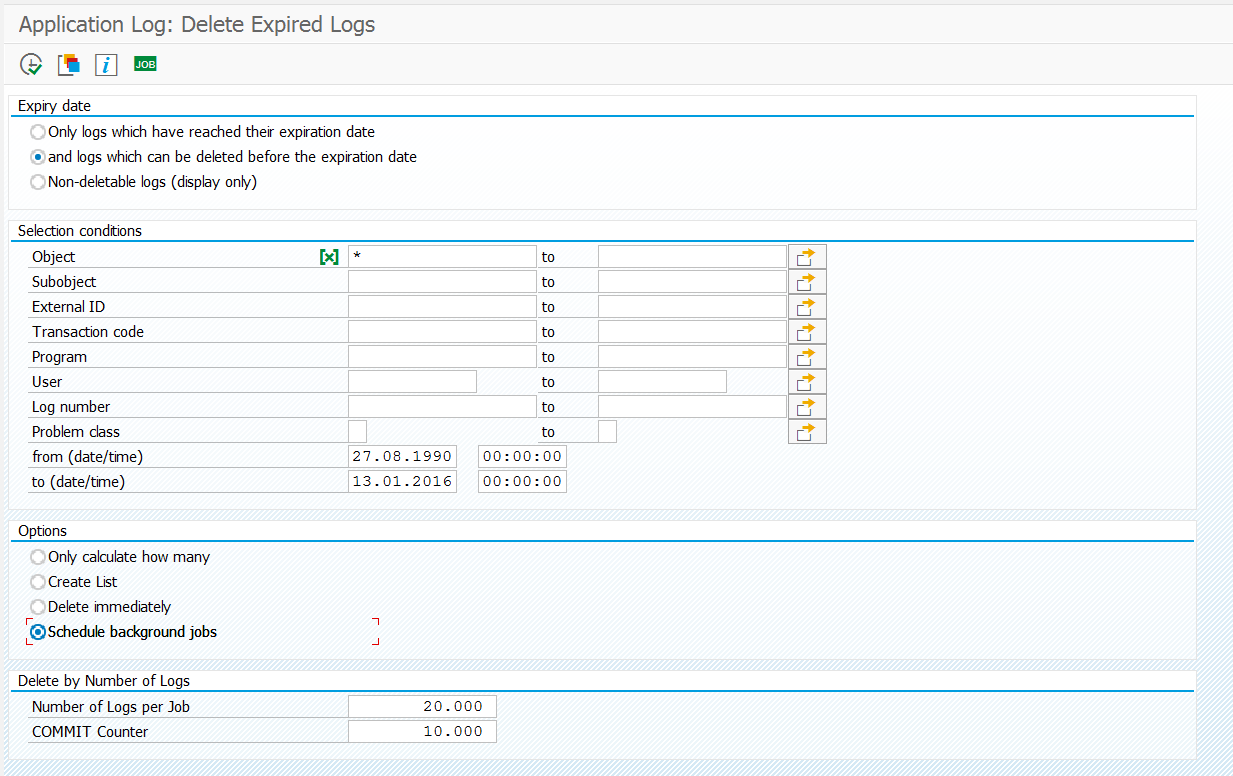
How can I clean up old application logs?
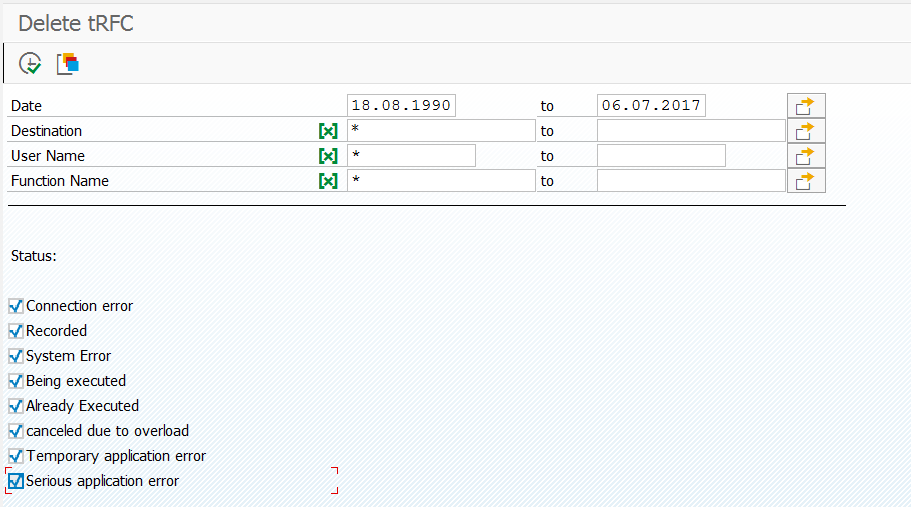
How can I clean up old RFC logs?
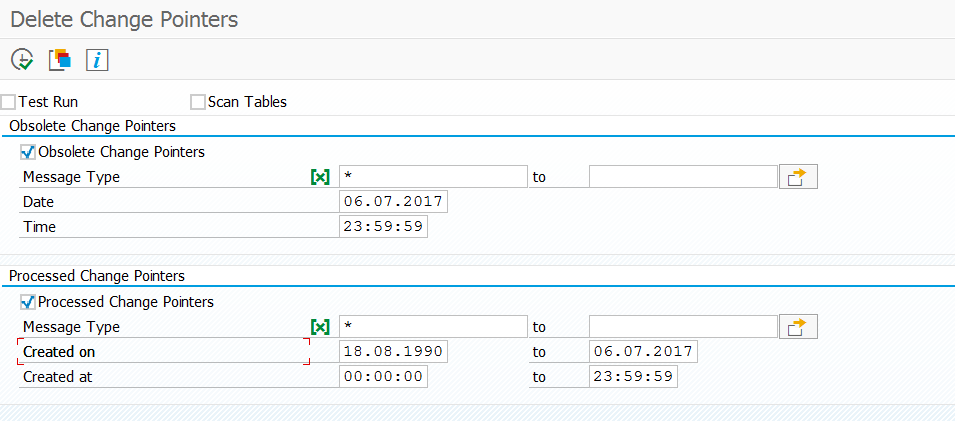
How can I clean up old change pointers?
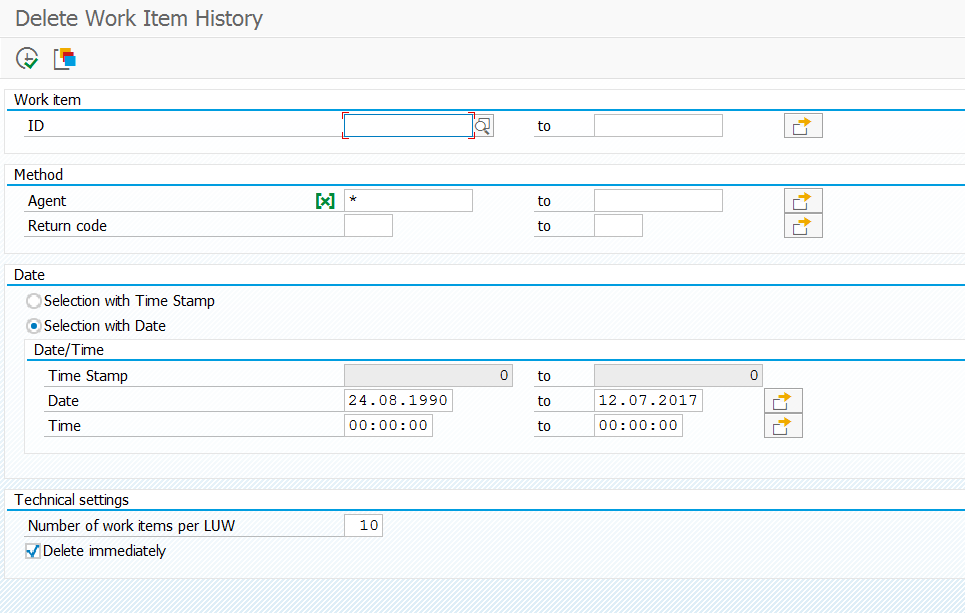
How can I delete workflow logging?
How can I archive workflows?
How can I delete SAP office documents?
How can I delete old audit log data?
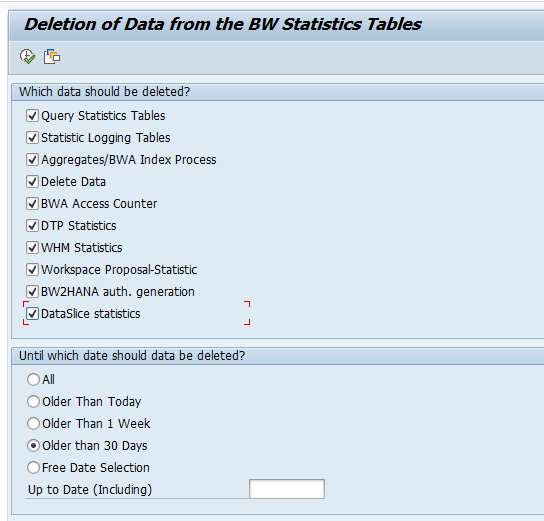
How can I execute specific clean up for BI systems?
How can I execute specific clean up for solution manager system?
Many more…. use search for table name
This blog assumes you have followed the step in this blog to get insight into your fast growing SAP tables. Or you use the me.sap.com/dataoverview function (see this blog for details).
In the past there was a function called data aging. This is superceded by HANA NSE (Native Storage Extension). To set up NSE, read the instructions in this blog.
This blog focuses on technical data objects archiving and clean up by performing deletion. If you want to setup functional archiving, start reading this blog.
Next to deletion, you can also offload a lot of technical tables from memory by using HANA NSE (native storage extension). Read more in this blog.
SAP standard clean up jobs
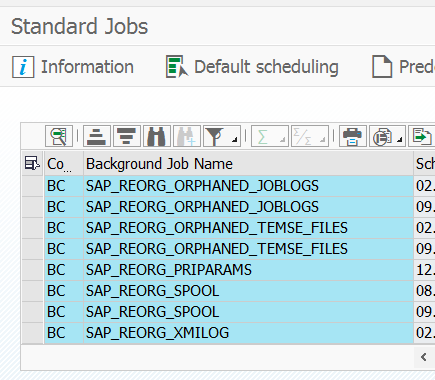
Using SM36 you can plan all SAP standard jobs (which include a lot of clean up jobs for spools, dumps, etc) via the button Standard Jobs.
By hitting the button Default scheduling in an initial system, or after any upgrade or support package, the system will plan its default clean up schedule.
S4HANA has different set up of standard jobs. See blog.
Clean up of old idocs
Idoc data is stored in EDI* tables. Largest tables are usually EDI40, EDIDS and EDIDC.
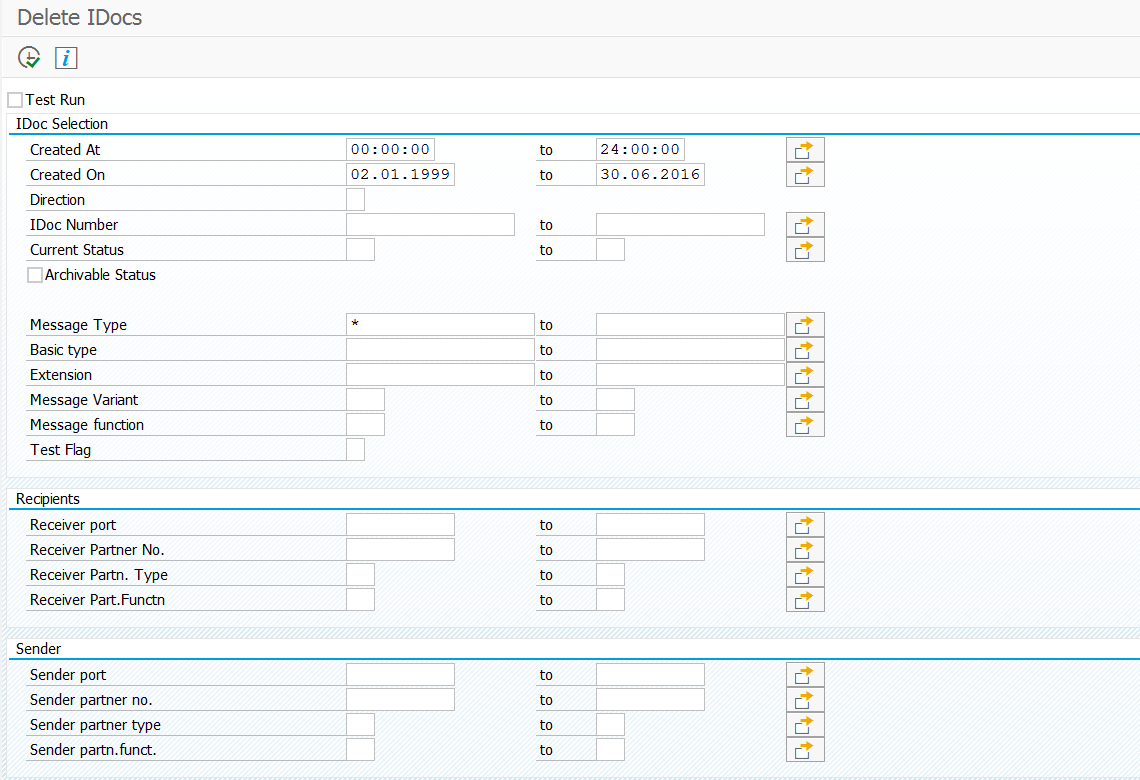
Old idocs can be deleted using transaction WE11.
In batch mode you can schedule it as program RSETESTD.
In the bottom of the selection screen are the technical options:
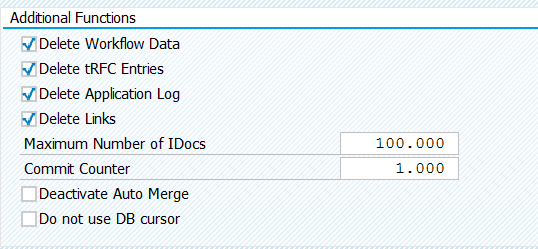
The idoc deletion job can fail if there is too many data to process. If they happens remove the 4 tick boxes here and use the separate deletion programs: RSWWWIDE, RSARFCER, SBAL_DELETE and RSRLDREL2. These 5 combined programs will delete the same, but run more efficiently. This procedure is also explained in OSS note 1574016 – Deleting idocs with WE11/ RSETESTD.
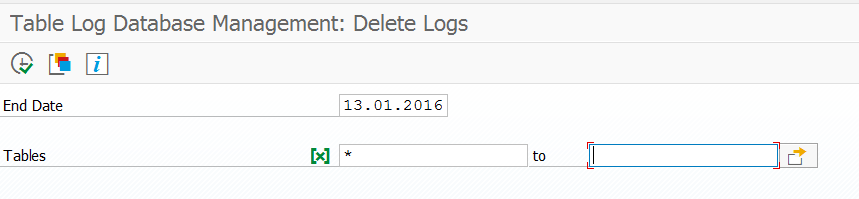
Table logging is stored in table DBTABLOG (general information on table logging can be found in this blog). Deletion can be done using transaction SCU3 and then choosing the option Edit/Logs/Delete, or by using program RSTBPDEL.
Application logging (SLG1) is stored in tables BALDAT and BALHDR (for general information on the use of the application log, read this blog). Deletion can be done using transaction SLG2 or by using program SBAL_DELETE.
The last options to fine tune the number of logs per job and the commit counter setting do not appear by default. Select menu option Program/Expert mode first.
Old RFC data can be deleted using transaction SM58, selecting some data, then in the overview screen select the menu option Log File/ Reorganize. Or by starting program RSARFCER.
If you are using MDG: it has its own set of change pointer tables (MDGD_CP_REP_STAT). Clean up transaction code is MDGCPDEL. Program for batch job clean up is RMDGCPCLR.
Workflows are stored in many tables starting with SW*.
You can delete work item history with transaction SWWH or program RSWWHIDE.
This clean up will only do the work item technical history and not the workflow itself. If workflow itself can be deleted or is to be archived is a functionality decision that the depend on the business and audit needs.
The workflow deleting program can create large amount of spools. If this is not wanted use the NULL printer.
If your business is using the GOS (generic object services) to see workflows linked to a business document, and they cannot retrieve the archived work item, please follow carefully the instructions in OSS note 2356250 – Not able to view archived workflows.
If you want to delete the actual workflow you have to run program RSWWWIDE.
Take care that before deleting workflows you have checked that these are not needed for audit or financial proof. Some workflows will contain approval steps with a recording of who approved what at which time.
If you have a large amount of items in your SAP inbox, you can delete them via program RSSODLIN. Background is in OSS note 63912 – SAPoffice: Delete user sessions.
Test this first and check with the data owner that the documents are no longer needed.
For a full explanation on deleting SAP office documents (including all the pre-programs to run) and bug fix notes: read this dedicated blog on SAP office document deletion.
After running RSBCS_REORG, consider also to run program RSBCS_ADRVP to clean up outdated where‑used lists for both personal (ADRVP) and company (ADRV) addresses that are no longer linked to any active BCS data.
Usually the business will not allow deletion of SAP office document (unless they are very old). You might be ending up with a SOFFCONT1 table of 100 GB or more.
In stead of deleting SAP office documents, you can also migrate them to a content server. Read more in this blog.
Change documents
Change documents do contain business data changes to business objects. If tables CDHDR and CDPOS grow very big, you start with an age analysis. You can propose to business to delete change documents older than 10 years. 10 years is the legal time you need to keep a lot of data. Deletion is done via program RSCDOK99. If business does not want to delete, but keep the data in the archive, you can use data archiving object CHANGEDOCU. Retrieval of archived change documents is via transaction RSSCD100.
If you have large SYS_LOB tables, most likely these are occupied with attachments. Consider setup of SAP content server (see blog) and then migrate the documents from the SAP database to the content server (see blog).
To analyze SYS_LOB tables, follow the instructions in this dedicated blog.
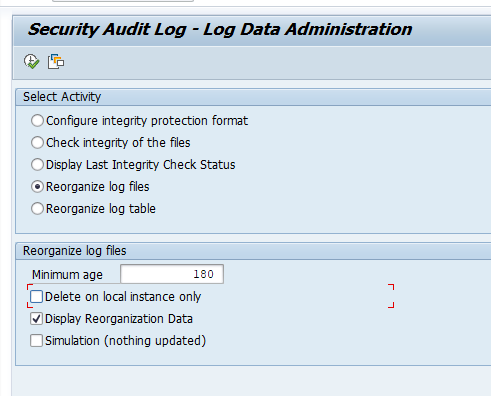
You can schedule program RSAUPURG or program RSAU_FILE_ADMIN with the right variant to delete old Audit log data:
Before deleting audit log data, first agree with your security officer on the retention period. More on audit log in this blog.
Clean up of user role assignment data
If you have an older system, you will find that many users will have double roles assigned, or roles with validity dates in the past. This will lead to large amount of entries in table AGR_USERS. You can clean up by compressing this data with program PRGN_COMPRESS_TIMES. Read more in this blog.
Large WBCROSSGT table
Table WBCROSSGT is used to store the ABAP where used index. Might be large after upgrade. Use program RS_DEL_WBCROSSGT to delete and program SAPRSEUB to recreate the indexes.
The master data replication framework can fill up table The master data replication framework can fill up table DRFD_SERVOUT_LOG fast with a lot of logging data. Run program RDRF_DELETE_LOG (transaction DRFLOGDEL) to clean up these logs.
For clean up of a solution manager system, read this dedicated blog.
Clean up for SAP Focused Run
For clean up of a SAP Focused Run system, read this dedicated blog.
Updating statistics
If you are running Oracle database it is wise to include in technical clean up job as last step the online reorganization of tables or indexes using program RSANAORA. See blog.